With today’s announcement of the second MySQL 5.7 Development Milestone Release and a new labs release it’s a very exciting time for MySQL Replication. MySQL 5.6 contained a lot of new content to make replication faster, easier to use and more reliable (Global Transaction Identifiers, Multi-Threaded Slaves, Binary Log Group Commit, Optimized Row Based Replication, Crash Safe Replication, Replication Event Checksums, Time Delayed Replication & Informational Logs) and now we want to improve things even further.
The new DMR has something for everyone.
With the improvements to Semi-Synchronous Replication, the application developer can be confident that when a transaction has been commited, the changes have been safely copied to one or more slaves and so whatever happens, that change will not be lost. Further, we now prevent other application threads seeing those changes until they’ve been received by the slave and so the application cannot start acting on the new data until it’s known to be safe. This is an important improvement in consistency which moves more of the onus from the application developer onto the database.
DBAs want replication to be fast – in particular for the slave(s) not to fall behind the master. MySQL 5.6 made some massive improvements in this area – both on the master and the slave. A number of users though were unable to exploit the Multi-Threaded Slave (MTS) feature as relied on the use of multiple schemas (databases) to get changes applied in parallel. In the new MySQL 5.7 DMR we’ve included a new option for MTS where changes can be applied in parallel – even within the same schema. A second performance feature improves throughput on the master – where the dump thread no longer needs to lock the binary log – refer to this engineering Blog on Dump Thread Enhancement in MySQL 5.7.2 for more details.
DBAs also want to monitor the status of replication and for years have relied on the SHOW SLAVE STATUS command. As replication has evolved, SHOW SLAVE STATUS has become less suitable – we needed a solution that could properly model the more sophisticated replication architectures (including GTIDs and MTS) now possible. The approach we’ve taken is to provide this information through the performance_schema.
Note that the earlier MySQL 5.7 DMR added non-blocking SHOW SLAVE STATUS, idempotent and –rewrite-db options for mysqlbinlog – these are still available in the new DMR.
The new features are described in a little more detail in the following sections (together with links to more technical content from the MySQL Engineeing team).
Loss-less Semi-Synchronous Replication
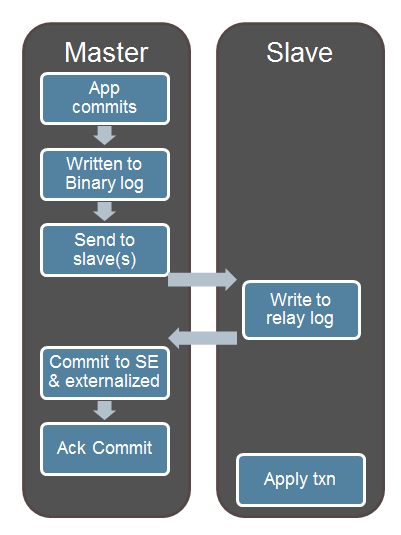
Intra-Schema Semi-Synchronous Replication
When using semi-synchronous replication in previous releases, the processing of the transaction on the master would wait for the slave’s acknowledgement after the change had been written to the storage engine but before the commit was acknowledged to the client. This satisfied the requirement that the application could be confident that if a transaction has been commited (and an acknowledgement received for the commit) then the update would not be lost. It did however leave a window where a user on another connection could read the new data from the master (because it has been written to the storage engine and the locks have been released) before the change had been received by the slave and safely stored in its relay log – that user could then start acting on that data but if the master failed at that point then that original update could still be lost and so the user would be acting on what is now inaccurate data.
This feature removes the above race condition by making the master wait for the update to be received by the slave before writing it to the storage engine and releasing the locks.
The functionality is enabled by default and shouldn’t have any negative impacts (for example on peformance) but it you’d like to disable it then you can do so using rpl_semi_sync_master_wait_point = AFTER_SYNC.
You can read more details on this in this Loss-less Semi-Synchronous Replication on MySQL 5.7.2 blog from the MySQL engineering team.
Intra-Schema Multi-Threaded Slaves
DBAs want replication to be fast – in particular for the slave(s) not to fall behind the master. If there is a short but heavy burst of writes on the master then the slave falls behind (and there is a risk of lost data if the master fails during this period) but if the write-rate is sustained then the slave would fall further and further behind indefinitely. The ongoing challenge has been that the master gets faster and faster as more cores and clients are added but applying these changes asynchronously on the slave is more complex as you need to maintain some form of ordering in order to always have a consistent data set.
The earliest solution to maintaining ordering/consistency was for the slave to apply all of the changes serially, in a single thread – this ensured that changes were applied in the same order as on the master and so guaranteed the slave always contained a consistent view. Unfortunately this meant that the slave applier thread could only exploit a single core which is very wasteful in modern systems.
MySQL 5.6 made some massive improvements for many use cases by allowing the slave to apply updates in parallel using multiple threads. The assumption made was that data was held in multiple schemas (databases) and that there were no dependencies between the data in those different schemas. In this way all of the updates for a schema would be applied in order by a single thread (ensuring consistency) but updates to other schemas could be handled by additional threads. This allowed the slave to work many times faster but was limited to those use cases that met the assumptions.
In the second MySQL 5.7 DMR we introduce a new option that enables the slave to safely apply updates in parallel – even when all of the data is held within a single schema and no assumptions can be made about the independence between any rows from any tables. To avoid conflicts/divergence from the master, the slave must ensure that any transactions that are applied in parallel don’t read or write any overlapping rows. The good news is that this grouping on non-overlapping transactions is already being figured out on the master as part of the binary log group commit functionality (introduced in MySQL 5.6) as row level locking means that overlapping transactions cannot be part of the same group commit.
MySQL 5.7 adds a logical clock/counter to the master which is used to tag transactions that are part of the same group commit’s prepare phase. The slave can then use that information – knowing that it is safe to apply all of the transactions with the same logical clock value in any order (and so can use multiple threads).
Activating the functionality is very straight-forward and the key step is to set slave-parallel-type = LOGICAL_CLOCK but see this blog from the MySQL engineering team: using the intra-schema MTS functionality for more detailed instructions. Note that there is another blog in the series – that blog provides a detailed view of how the intra-schema MTS is implemented.
Replication Performance Schema
With the ever increasing sophistication of MySQL Replication, presenting all of the information in SHOW SLAVE STATUS has become unwieldy with data for multiple slave applier threads, GTID sets etc. What would be much more convenient is if this information were presented in tables so that the user could get exactly the information they needed using SQL queries (plus of course we can lay out the data in an understandable (relational) way and can access the information from stored procedures). MySQL 5.7.2 does just this by adding MySQL Replication tables to the MySQL performance_schema.
This feature introduces 6 new performance_schema tables: replication_connection_configuration, replication_connection_status, replication_execute_configuration, replication_execute_status, replication_execute_status_by_coordinator, replication_execute_status_by_worker.
Shivji from the MySQL engineering team has written a great blog post on what’s in the new performance_schema tables and how to interpret the results.
Multi-Source Replication – LABS

Multi-Source Replication
MySQL replication is very flexible in the way that networks of masters and slaves that can be built up; a master can replicate to multiple slaves, a master can itself be a slave of another master, you can create a replication ring…. The one caveat to this has always been that a slave server can only have a single master (MySQL Cluster is an exception to this rule).
Why might you want to do this? There are a few use cases around consolidating data from multiple MySQL Servers into one:
– Where each of the masters is for a different shard (where the application is responsible for the sharding) and you want to be able to run reports over all of that data to produce a consolidated view
– You want to avoid the expense of dedicating a slave server to each master server
– A remote location may require less throughput and so a single server can service all of the traffic for all of the data – the ‘super-slave’ gives it a low-overhead, local database to access all of the data
– The ‘super-slave’ is used as a point where you can perform backups for all of the data
It’s possible to have a slave time-slice between multiple masters with a bit of scripting but that isn’t an ideal solution. You can also add an additional repliation layer (such as writing your own code to use the binary log API) but it would be much simpler if it were built into MySQL itself.
In this labs (i.e. for test only, not to be deployed!) release we allow a slave to simultaneously receive and process replication events from multiple masters – exactly what our users have been asking for.
What’s more, we’ve also ensured that this new functionality is compatible with the other enhancements that have been made to the MySQL Replication architecture – this includes loss-less semi-synchronus replication; and intra-schema multi-threaded slaves (as well as the existing per-database MTS). This means that you don’t have to choose between all of these tempting features – the keys to the candy store are yours!
It’s likely that not all of the masters will be the same, have the same maintenance schedules etc. and so it makes sense to be able to manage each of the relationships independently. In this labs release you can manage each master independently, including the relevant server variables but the same replication filters are currently applied to the replication events from all of the masters – we recognise that this isn’t ideal but this is cuurently an early access release and it’s something we intend to address in future versions.
At the moment there’s no limit to the number of masters that can replicate to a specific slave – in the final version we’re likely to apply a configurable limit.
Because this further complicates the information that would need to be included in SHOW SLAVE STATUS, most of the detailed information is instead presented in the Performance Schema.
It should be pointed out that there is no conflict detection or resolution built into this feature – it is the responsibility of the application to make sure that the masters are working on distinct data sets (or that they’re comfortable with the results of any conflicts).
For more technical details, refer to this engineering blog post on multi-source replication.
Summary
There’s a lot of exciting new content in the MySQL 5.7.2 DMR (download here) and the Mulit-Source Replication labs release (download here). The reason these features has been released is that we value early feedback from our community and customers – please try them out and let us know what we’re getting right and what needs to be enhanced!