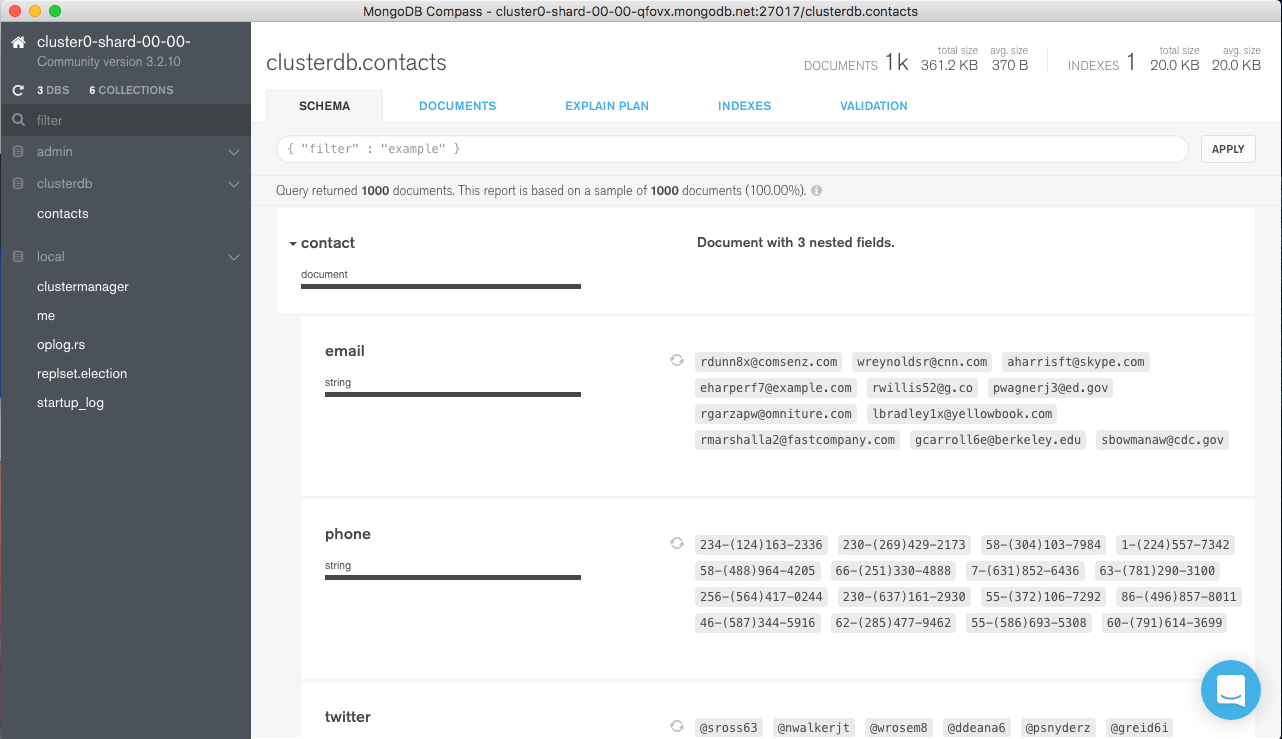
Introducing the MEAN and MERN stacks
This is the first in a series of blog posts examining the technologies that are driving the development of modern web and mobile applications, notably the MERN and MEAN stacks. The series will go on to step through tutorials to build all layers of an application.
Users increasingly demand a far richer experience from web sites – expecting the same level of performance and interactivity they get with native desktop and mobile apps. At the same time, there’s pressure on developers to deliver new applications faster and continually roll-out enhancements, while ensuring that the application is highly available and can be scaled appropriately when needed. Fortunately, there’s a (sometimes bewildering) set of enabling technologies that make all of this possible.
If there’s one thing that ties these technologies together, it’s JavaScript and its successors (ES6, TypeScript, JSX, etc.) together with the JSON data format. The days when the role of JavaScript was limited to adding visual effects like flashing headers or pop-up windows are past. Developers now use JavaScript to implement the front-end experience as well as the application logic and even to access the database. There are two dominant JavaScript web app stacks – MEAN (MongoDB, Express, Angular, Node.js) and MERN (MongoDB, Express, React, Node.js) and so we’ll use those as paths to guide us through the ever-expanding array of tools and frameworks.
This first post serves as a primer for many of these technologies. Subsequent posts in the series take a deep dive into specific topics – working through the end-to-end development of Mongopop – an application to populate a MongoDB database with realistic data and then perform other operations on that data.
The MEAN Stack
We’ll start with MEAN as it’s the more established stack but most of what’s covered here is applicable to MERN (swap Angular with React).
MEAN is a set of Open Source components that together, provide an end-to-end framework for building dynamic web applications; starting from top (code running in the browser) to the bottom (database). The stack is made up of:
- Angular (formerly Angular.js, now also known as Angular 2): Front-end web app framework; runs your JavaScript code in the users browser, allowing your application UI to be dynamic
- Express (sometimes referred to as Express.js): Back-end web application framework running on top of Node.js
- Node.js : JavaScript runtime environment – lets you implement your application back-end in JavaScript
- MongoDB : Document database – used by your back-end application to store its data as JSON (JavaScript Object Notation) documents
A common theme in the MEAN stack is JavaScript – every line of code you write can be in the same language. You even access the database using MongoDB’s native, Idiomatic JavaScript/Node.js driver. What do we mean by idiomatic? Using the driver feels natural to a JavaScript developer as all interaction is performed using familiar concepts such as JavaScript objects and asynchronous execution using either callback functions or promises (explained later). Here’s an example of inserting an array of 3 JavaScript objects:
myCollection.insertMany([
{name: {first: "Andrew", last: "Morgan"},
{name: {first: "Elvis"}, died: 1977},
{name: {last: "Mainwaring", title: "Captain"}, born: 1885}
])
.then(
function(results) {
resolve(results.insertedCount);
},
function(err) {
console.log("Failed to insert Docs: " + err.message);
reject(err);
}
)
Angular 2
Angular, originally created and maintained by Google, runs your JavaScript code within the user’s web browsers to implement a reactive user interface (UI). A reactive UI gives the user immediate feedback as they give their input (in contrast to static web forms where you enter all of your data, hit “Submit” and wait.

Version 1 of Angular was called AngularJS but it was shortened to Angular in Angular 2 after it was completely rewritten in Typescript (a superset of JavaScript) – Typescript is now also the recommended language for Angular apps to use.
You implement your application front-end as a set of components – each of which consists of your JavaScript (TypeScript) code and an HTML template that includes hooks to execute and use the results from your TypeScript functions. Complex application front-ends can be crafted from many simple (optionally nested) components.
Angular application code can also be executed on the back-end server rather than in a browser, or as a native desktop or mobile application.

Express
Express is the web application framework that runs your back-end application (JavaScript) code. Express runs as a module within the Node.js environment.
Express can handle the routing of requests to the right parts of your application (or to different apps running in the same environment).
You can run the app’s full business logic within Express and even generate the final HTML to be rendered by the user’s browser. At the other extreme, Express can be used to simply provide a REST API – giving the front-end app access to the resources it needs e.g., the database.
In this blog series, we will use Express to perform two functions:
- Send the front-end application code to the remote browser when the user browses to our app
- Provide a REST API that the front-end can access using HTTP network calls, in order to access the database
Node.js
Node.js is a JavaScript runtime environment that runs your back-end application (via Express).
Node.js is based on Google’s V8 JavaScript engine which is used in the Chrome browsers. It also includes a number of modules that provides features essential for implementing web applications – including networking protocols such as HTTP. Third party modules, including the MongoDB driver, can be installed, using the npm tool.
Node.js is an asynchronous, event-driven engine where the application makes a request and then continues working on other useful tasks rather than stalling while it waits for a response. On completion of the requested task, the application is informed of the results via a callback. This enables large numbers of operations to be performed in parallel which is essential when scaling applications. MongoDB was also designed to be used asynchronously and so it works well with Node.js applications.
MongoDB
MongoDB is an open-source, document database that provides persistence for your application data and is designed with both scalability and developer agility in mind. MongoDB bridges the gap between key-value stores, which are fast and scalable, and relational databases, which have rich functionality. Instead of storing data in rows and columns as one would with a relational database, MongoDB stores JSON documents in collections with dynamic schemas.
MongoDB’s document data model makes it easy for you to store and combine data of any structure, without giving up sophisticated validation rules, flexible data access, and rich indexing functionality. You can dynamically modify the schema without downtime – vital for rapidly evolving applications.
It can be scaled within and across geographically distributed data centers, providing high levels of availability and scalability. As your deployments grow, the database scales easily with no downtime, and without changing your application.
MongoDB Atlas is a database as a service for MongoDB, letting you focus on apps instead of ops. With MongoDB Atlas, you only pay for what you use with a convenient hourly billing model. With the click of a button, you can scale up and down when you need to, with no downtime, full security, and high performance.
Our application will access MongoDB via the JavaScript/Node.js driver which we install as a Node.js module.
What’s Done Where?
tl;dr – it’s flexible.
There is clear overlap between the features available in the technologies making up the MEAN stack and it’s important to decide “who does what”.
Perhaps the biggest decision is where the application’s “hard work” will be performed. Both Express and Angular include features to route to pages, run application code, etc. and either can be used to implement the business logic for sophisticated applications. The more traditional approach would be to do it in the back-end in Express. This has several advantages:
- Likely to be closer to the database and other resources and so can minimise latency if lots of database calls are made
- Sensitive data can be kept within this more secure environment
- Application code is hidden from the user, protecting your intellectual property
- Powerful servers can be used – increasing performance
However, there’s a growing trend to push more of the functionality to Angular running in the user’s browser. Reasons for this can include:
- Use the processing power of your users’ machines; reducing the need for expensive resources to power your back-end. This provides a more scalable architecture, where every new user brings their own computing resources with them.
- Better response times (assuming that there aren’t too many trips to the back-end to access the database or other resources)
- Progressive Applications. Continue to provide (probably degraded) service when the client application cannot contact the back-end (e.g. when the user has no internet connection). Modern browsers allow the application to store data locally and then sync with the back-end when connectivity is restored.
Perhaps, a more surprising option for running part of the application logic is within the database. MongoDB has a sophisticated aggregation framework which can perform a lot of analytics – often more efficiently than in Express or Angular as all of the required data is local.
Another decision is where to validate any data that the user supplies. Ideally, this would be as close to the user as possible – using Angular to check that a provided password meets security rules allows for instantaneous feedback to the user. That doesn’t mean that there isn’t value in validating data in the back-end as well, and using MongoDB’s document validation functionality can guard against buggy software writing erroneous data.
ReactJS – Rise of the MERN Stack

An alternative to Angular is React (sometimes referred to as ReactJS), a JavaScript library developed by Facebook to build interactive/reactive user interfaces. Like Angular, React breaks the front-end application down into components. Each component can hold its own state and a parent can pass its state down to its child components and those components can pass changes back to the parent through the use of callback functions.
React components are typically implemented using JSX – an extension of JavaScript that allows HTML syntax to be embedded within the code:
class HelloMessage extends React.Component {
render() {
return <div>Hello {this.props.name}</div>;
}
}
React is most commonly executed within the browser but it can also be run on the back-end server within Node.js, or as a mobile app using React Native.
So should you use Angular 2 or React for your new web application? A quick google search will find you some fairly deep comparisons of the two technologies but in summary, Angular 2 is a little more powerful while React is easier for developers to get up to speed with and use. This blog series will build a near-identical web app using first the MEAN and then the MERN stack – hopefully these posts will help you find a favorite.
The following snapshot from Google Trends suggests that Angular has been much more common for a number of years but that React is gaining ground:

Why are these stacks important?
Having a standard application stack makes it much easier and faster to bring in new developers and get them up to speed as there’s a good chance that they’ve used the technology elsewhere. For those new to these technologies, there exist some great resources to get you up and running.
From MongoDB upwards, these technologies share a common aim – look after the critical but repetitive stuff in order to free up developers to work where they can really add value: building your killer app in record time.
These are the technologies that are revolutionising the web, building web-based services that look, feel, and perform just as well as native desktop or mobile applications.
The separation of layers, and especially the REST APIs, has led to the breaking down of application silos. Rather than an application being an isolated entity, it can now interact with multiple services through public APIs:
- Register and log into the application using my Twitter account
- Identify where I want to have dinner using Google Maps and Foursquare
- Order an Uber to get me there
- Have Hue turn my lights off and Nest turn my heating down
- Check in on Facebook
- …
Variety & Constant Evolution
Even when constraining yourself to the JavaScript ecosystem, the ever-expanding array of frameworks, libraries, tools, and languages is both impressive and intimidating at the same time. The great thing is that if you’re looking for some middleware to perform a particular role, then the chances are good that someone has already built it – the hardest part is often figuring out which of the 5 competing technologies is the best fit for you.
To further complicate matters, it’s rare for the introduction of one technology not to drag in others for you to get up to speed on: Node.js brings in npm; Angular 2 brings in Typescript, which brings in tsc; React brings in ES6, which brings in Babel; ….
And of course, none of these technologies are standing still and new versions can require a lot of up-skilling to use – Angular 2 even moved to a different programming language!
The Evolution of JavaScript
The JavaScript language itself hasn’t been immune to change.
Ecma International was formed to standardise the language specification for JavaScript (and similar language forks) to increase portability – the ideal being that any “JavaScript” code can run in any browser or other JavaScript runtime environment.
The most recent, widely supported version is ECMAScript 6 – normally referred to as ES6. ES6 is supported by recent versions of Chrome, Opera, Safari, and Node.js). Some platforms (e.g. Firefox and Microsoft Edge) do not yet support all features of ES6. These are some of the key features added in ES6:
- Classes & modules
- Promises – a more convenient way to handle completion or failure of synchronous function calls (compared to callbacks)
- Arrow functions – a concise syntax for writing function expressions
- Generators – functions that can yield to allow others to execute
- Iterators
- Typed arrays
Typescript is a superset of ES6 (JavaScript); adding static type checking. Angular 2 is written in Typescript and Typescript is the primary language to be used when writing code to run in Angular 2.
Because ES6 and Typescript are not supported in all environments, it is common to transpile the code into an earlier version of JavaScript to make it more portable. In this series’ Angular post, tsc is used to transpile Typescript into JavaScript while the React post uses Babel (via react-script) to transpile our ES6 code.
And of course, JavaScript is augmented by numerous libraries. The Angular 2 post in this series uses Observables from the RxJS reactive libraries which greatly simplify making asynchronous calls to the back-end (a pattern historically referred to as AJAX).
Summary & What’s Next in the Series
This post has introduced some of the technologies used to build modern, reactive, web applications – most notably the MEAN and MERN stacks. If you want to learn exactly how to use these then please continue to follow this blog series which steps through building the MongoPop application:
- Part 1: Introducing The MEAN Stack (and the young MERN upstart)
- Part 2: Using MongoDB With Node.js
- Part 3: Building a REST API with Express.js
- Part 4: Building a Client UI Using Angular 2 (formerly AngularJS) & TypeScript
- Part 5: Using ReactJS, ES6 & JSX to Build a UI (the rise of MERN)
- Part 6: Browsers Aren’t the Only UI – Mobile Apps, Amazon Alexa, Cloud Services…
As already covered in this post, the MERN and MEAN stacks are evolving rapidly and new JavaScript frameworks are being added all of the time. Inevitably, some of the details in this series will become dated but the concepts covered will remain relevant.
A simpler way to build your app – MongoDB Stitch, Backend as a Service
MongoDB Stitch is a backend as a service (BaaS), giving developers a REST-like API to MongoDB, and composability with other services, backed by a robust system for configuring fine-grained data access controls. Stitch provides native SDKs for JavaScript, iOS, and Android.
Built-in integrations give your application frontend access to your favorite third party services: Twilio, AWS S3, Slack, Mailgun, PubNub, Google, and more. For ultimate flexibility, you can add custom integrations using MongoDB Stitch’s HTTP service.
MongoDB Stitch allows you to compose multi-stage pipelines that orchestrate data across multiple services; where each stage acts on the data before passing its results on to the next.
Unlike other BaaS offerings, MongoDB Stitch works with your existing as well as new MongoDB clusters, giving you access to the full power and scalability of the database. By defining appropriate data access rules, you can selectively expose your existing MongoDB data to other applications through MongoDB Stitch’s API.
If you’d like to try it out, step through building an application with MongoDB Stitch.