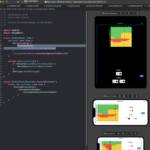
I wanted to build an app that we could use at events to demonstrate Realm Sync. It needed to be fun to interact with, and so a multiplayer game made sense. Tic-tac-toe is too simple to get excited about. I’m not a game developer and so Call Of Duty wasn’t an option. Then I remembered Microsoft’s Minesweeper.
Minesweeper was a Windows fixture from 1990 until Windows 8 relegated it to the app store in 2012. It was a single-player game, but it struck me as something that could be a lot of fun to play with others. Some family beta-testing of my first version while waiting for a ferry proved that it did get people to interact with each other (even if most interactions involved shouting, “Which of you muppets clicked on that mine?!”).

You can download the back end and iOS apps from the Realm-Sweeper repo, and get it up and running in a few minutes if you want to play with it.
This article steps you through some of the key aspects of setting up the backend Realm app, as well as the iOS code. Hopefully, you’ll see how simple it is and try building something for yourself. If anyone’s looking for ideas, then Sokoban could be interesting.
Prerequisites
- Realm-Cocoa 10.20.1+
- iOS 15+
The Minesweeper game
The gameplay for Minesweeper is very simple.
You’re presented with a grid of gray tiles. You tap on a tile to expose what’s beneath. If you expose a mine, game over. If there isn’t a mine, then you’ll be rewarded with a hint as to how many mines are adjacent to that tile. If you deduce (or guess) that a tile is covering a mine, then you can plant a flag to record that.
You win the game when you correctly flag every mine and expose what’s behind every non-mined tile.
What Realm-Sweeper adds
Minesweeper wasn’t designed for touchscreen devices; you had to use a physical mouse. Realm-Sweeper brings the game into the 21st century by adding touch controls. Tap a tile to reveal what’s beneath; tap and hold to plant a flag.
Minesweeper was a single-player game. All people who sign into Realm-Sweeper with the same user ID get to collaborate on the same game in real time.

You also get to configure the size of the grid and how many mines you’d like to hide.
The data model
I decided to go for a simple data model that would put Realm sync to the test.
Each game is a single document/object that contains meta data (score, number of rows/columns, etc.) together with the grid of tiles (the board):

This means that even a modestly sized grid (20×20 tiles) results in a Game document/object with more than 2,000 attributes.
Every time you tap on a tile, the Game object has to be synced with all other players. Those players are also tapping on tiles, and those changes have to be synced too. If you tap on a tile which isn’t adjacent to any mines, then the app will recursively ripple through exposing similar, connected tiles. That’s a lot of near-simultaneous changes being made to the same object from different devices—a great test of Realm’s automatic conflict resolution!
The backend Realm app
If you don’t want to set this up yourself, simply follow the instructions from the repo to import the app.
If you opt to build the backend app yourself, there are only two things to configure once you create the empty Realm app:
- Enable email/password authentication. I kept it simple by opting to auto-confirm new users and sticking with the default password-reset function (which does nothing).
- Enable partitioned Realm sync. Set the partition key to
partitionand enable developer mode (so that the schema will be created automatically when the iOS app syncs for the first time).
The partition field will be set to the username—allowing anyone who connects as that user to sync all of their games.
You can also add sync rules to ensure that a user can only sync their own games (in case someone hacks the mobile app). I always prefer using Realm functions for permissions. You can add this for both the read and write rules:
{
"%%true": {
"%function": {
"arguments": [
"%%partition"
],
"name": "canAccessPartition"
}
}
}
The canAccessPartition function is:
exports = function(partition) {
const user = context.user.data.email;
return partition === user;
};
The iOS app
I’d suggest starting by downloading, configuring, and running the app—just follow the instructions from the repo. That way, you can get a feel for how it works.
This isn’t intended to be a full tutorial covering every line of code in the app. Instead, I’ll point out some key components.
As always with Realm and MongoDB, it all starts with the data…
Model
There’s a single top-level Realm Object—Game:
class Game: Object, ObjectKeyIdentifiable {
@Persisted(primaryKey: true) var _id: ObjectId
@Persisted var numRows = 0
@Persisted var numCols = 0
@Persisted var score = 0
@Persisted var startTime: Date? = Date()
@Persisted var latestMoveTime: Date?
@Persisted var secondsTakenToComplete: Int?
@Persisted var board: Board?
@Persisted var gameStatus = GameStatus.notStarted
@Persisted var winningTimeInSeconds: Int?
…
}
Most of the fields are pretty obvious. The most interesting is board, which contains the grid of tiles:
class Board: EmbeddedObject, ObjectKeyIdentifiable {
@Persisted var rows = List<Row>()
@Persisted var startingNumberOfMines = 0
...
}
row is a list of Cells:
class Row: EmbeddedObject, ObjectKeyIdentifiable {
@Persisted var cells = List<Cell>()
...
}
class Cell: EmbeddedObject, ObjectKeyIdentifiable {
@Persisted var isMine = false
@Persisted var numMineNeigbours = 0
@Persisted var isExposed = false
@Persisted var isFlagged = false
@Persisted var hasExploded = false
...
}
The model is also where the ~~business~~ game logic is implemented. This means that the views can focus on the UI. For example, Game includes a computed variable to check whether the game has been solved:
var hasWon: Bool {
guard let board = board else { return false }
if board.remainingMines != 0 { return false }
var result = true
board.rows.forEach() { row in
row.cells.forEach() { cell in
if !cell.isExposed && !cell.isFlagged {
result = false
return
}
}
if !result { return }
}
return result
}
Views
As with any SwiftUI app, the UI is built up of a hierarchy of many views.

Here’s a quick summary of the views that make up Real-Sweeper:
ContentView is the top-level view. When the app first runs, it will show the LoginView. Once the user has logged in, it shows GameListView instead. It’s here that we set the Realm Sync partition (to be the username of the user that’s just logged in):
if username == "" {
LoginView(username: $username)
} else {
GameListView()
.environment(\.realmConfiguration, realmApp.currentUser!.configuration(partitionValue: username))
.navigationBarItems(leading: realmApp.currentUser != nil ? LogoutButton(username: $username) : nil)
}
ContentView also includes the LogoutButton view.
LoginView allows the user to provide a username and password:

Those credentials are then used to register or log into the backend Realm app:
func userAction() {
Task {
do {
if newUser {
try await realmApp.emailPasswordAuth.registerUser(
email: email, password: password)
}
let _ = try await realmApp.login(
credentials: .emailPassword(email: email, password: password))
username = email
} catch {
errorMessage = error.localizedDescription
}
}
}
GameListView reads the list of this user’s existing games.
@ObservedResults(Game.self,
sortDescriptor: SortDescriptor(keyPath: "startTime", ascending: false)) var games
It displays each of the games within a GameSummaryView. If you tap one of the games, then you jump to a GameView for that game:
NavigationLink(destination: GameView(game: game)) {
GameSummaryView(game: game)
}

Tap the settings button and you’re sent to SettingsView.
Tap the “New Game” button and a new Game object is created and then stored in Realm by appending it to the games live query:
private func createGame() {
numMines = min(numMines, numRows * numColumns)
game = Game(rows: numRows, cols: numColumns, mines: numMines)
if let game = game {
$games.append(game)
}
startGame = true
}
SettingsView lets the user choose the number of tiles and mines to use:

If the user uses multiple devices to play the game (e.g., an iPhone and an iPad), then they may want different-sized boards (taking advantage of the extra screen space on the iPad). Because of that, the view uses the device’s UserDefaults to locally persist the settings rather than storing them in a synced realm:
@AppStorage("numRows") var numRows = 10
@AppStorage("numColumns") var numColumns = 10
@AppStorage("numMines") var numMines = 15
GameSummaryView displays a summary of one of the user’s current or past games.

GameView shows the latest stats for the current game at the top of the screen:

It uses the LEDCounter and StatusButton views for the summary.
Below the summary, it displays the BoardView for the game.
LEDCounter displays the provided number as three digits using a retro LED font:

StatusButton uses a ZStack to display the symbol for the game’s status on top of a tile image:

The view uses SwiftUI’s GeometryReader function to discover how much space is available so that it can select an appropriate font size for the symbol:
GeometryReader { geo in
Text(status)
.font(.system(size: geo.size.height * 0.7))
}
BoardView displays the game’s grid of tiles:

Each of the tiles is represented by a CellView view.
When a tile is tapped, this view exposes its contents:
.onTapGesture() {
expose(row: row, col: col)
}
On a tap-and-hold, a flag is dropped:
.onLongPressGesture(minimumDuration: 0.1) {
flag(row: row, col: col)
}
When my family tested the first version of the app, they were frustrated that they couldn’t tell whether they’d held long enough for the flag to be dropped. This was an easy mistake to make as their finger was hiding the tile at the time—an example of where testing with a mouse and simulator wasn’t a substitute for using real devices. It was especially frustrating as getting it wrong meant that you revealed a mine and immediately lost the game. Fortunately, this is easy to fix using iOS’s haptic feedback:
func hapticFeedback(_ isSuccess: Bool) {
let generator = UINotificationFeedbackGenerator()
generator.notificationOccurred(isSuccess ? .success : .error)
}
You now feel a buzz when the flag has been dropped.
CellView displays an individual tile:

What’s displayed depends on the contents of the Cell and the state of the game. It uses four further views to display different types of tile: FlagView, MineCountView, MineView, and TileView.




Conclusion
Realm-Sweeper gives a real feel for how quickly Realm is able to synchronize data over the internet.
I intentionally avoided optimizing how I updated the game data in Realm. When you see a single click exposing dozens of tiles, each cell change is an update to the Game object that needs to be synced.

Note that both instances of the game are running in iPhone simulators on an overworked Macbook in England. The Realm backend app is running in the US—that’s a 12,000 km/7,500 mile round trip for each sync.
I took this approach as I wanted to demonstrate the performance of Realm synchronization. If an app like this became super-popular with millions of users, then it would put a lot of extra strain on the backend Realm app.
An obvious optimization would be to condense all of the tile changes from a single tap into a single write to the Realm object. If you’re interested in trying that out, just fork the repo and make the changes. If you do implement the optimization, then please create a pull request. (I’d probably add it as an option within the settings so that the “slow” mode is still an option.)
Got questions? Ask them in our Community forum.















 RCurrency app, I was able to replace this
RCurrency app, I was able to replace this