I was rooting through past blog entries and I stumbled accross a draft post on setting up multi-master (update anywhere) asynchronous replication for MySQL Cluster. The post never quite got finished and published and while the material is now 4 years old it may still be helpfull to some and so I’m posting it now. Note that a lot has happened with MySQL Cluster in the last 4 years and in this area, the most notable change has been the Enhanced conflict resolution with MySQL Cluster active-active replication feature introduced in MySQL Cluster 7.2 and if you’re only dealing with a pair of Clusters, that’s your best option as it removed the need for you to maintain the timestamp columns and backs out entire transactions rather than just the conflicting rows. So when would you use this “legacy” method? The main use case is when you want conflict detection/resolution among a ring of more than 2 Clusters. Note also that MySQL 5.6 (and so MySQL Cluster 7.3) added microsecond precision to timestamps and so you may not need the custom plugin that this post referred to.
Anyway, here’s the original post…
————————————————————
MySQL Cluster asynchronous replication allows you to run in a multi-master mode with the application making changes to both sites (or more than 2 sites using a replication ring). As the replication is asynchronous, if the application(s) modified the same row on both sites at ‘about the same time’ then there is a potential for a collision. Left to their own devices, each site would store (and provide to the application) different data indefinitely. This article explains how to use MySQL Cluster collision detection and resolution to cope with this.

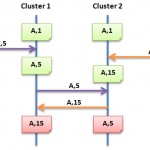
Fig. 1 Multi-master replication leading to inconsistencies
Fig. 1 shows the timeline that can result in a conflict. The same or two different applications make a change to the same row in the table but to the 2 different instances of MySQL Cluster. Each cluster synchronously replicates the data amongst its local data node in order to provide local High Availability (everything there is safe!). At some point later (normally a fraction of a second), the changes are replicated to the remote site asynchronously – this delay opens a window for a conflict where Cluster 2 is updated by the application just before it receives the earlier update from Cluster 1. Cluster 2 will overwrite it’s row with the value (5) it has received but only after its earlier change (directly from the application) is written to the binary log ready for replication to Cluster 1 which in turn will cause that value (15) to be stored by Cluster 1. Each Cluster instance replicates what it believes to be the correct data to the other site – overwriting what that site had previously stored. In our example, that leaves one database holding the value 15 for key ‘A’ while the other stores 5.
It’s often the case that the application will tend to go to the same site during a particular time when accessing the same data and so the chances of a conflict are reduced but the application may still want to guard against (even rare) race conditions. If replication slows down (for example due to a backlog of updates to be applied) or stops temporarily (for example due to network failure to the geographically remote site) then the chances of a collision greatly increase.
For information on setting up multi-master asynchronous replication with MySQL Cluster, please take a look at Setting up MySQL Asynchronous Replication for High Availability.
Conflict Detection & Resolution using MySQL Cluster
MySQL Cluster provides two different schemes to handle these collisions/conflicts. The first scheme (referred to as “greatest timestamp wins”) detects that a conflict occurs and automatically resolves it (the change most recently received from the application is stored on both Clusters). The second scheme (referred to as “same value wins”) detects that a conflict has occurred but does not fix it – instead the conflict is recorded in such a way that the application (or user) can figure out how best to resolve it based on a full understanding of the schema, what the data means and how it’s used. It is up to the developer which approach they use (if any) – it is selected on a per-table basis.
Common prerequisite steps
These steps should be followed regardless of whether you want to use conflict resolution or conflict detection (where the application decides how to resolve it).
- Set up multi-master replication as described in Setting up MySQL Asynchronous Replication for High Availability
- Create the function “inttime” for use in the stored procedures as described in Creating a MySQL plugin to produce an integer timestamp Note that you will need to install inttime.so on each host
Setting up Automatic Conflict Resolution (Greatest timestamp wins)
This is the simplest way to handle conflicts with MySQL Cluster when implementing multi-master asynchronous replication (actually, the simplest is to do nothing and accept that if your application(s) update the same row at about the same time at both Clusters then those Clusters may be left with different data until the application(s) next update that row).
Remember that this mechanism works by checking that the timestamp field of the update received by the slave is later than the one already stored. In the example that follows, the ‘ts’ column is used for the timestamp.
Create the database on either cluster (replication will make sure that it appears in both Clusters):
mysql> create database clusterdb;
Before creating the application tables, set up the ndb_replication system table (again, in either Cluster):
mysql> CREATE TABLE mysql.ndb_replication ( db VARBINARY(63), table_name VARBINARY(63), server_id INT UNSIGNED, binlog_type INT UNSIGNED, conflict_fn VARBINARY(128), PRIMARY KEY USING HASH (db, table_name, server_id) ) ENGINE=NDB PARTITION BY KEY(db,table_name);
mysql> insert into mysql.ndb_replication values ('clusterdb', 'tab1', 7, NULL, 'NDB$MAX(ts)');
After that, you can create the application table:
cluster1 mysql> use clusterdb;
cluster1 mysql> create table tab1 (NAME varchar(30) not null primary key,VALUE int, ts BIGINT UNSIGNED default NULL) engine=ndb;
To test that the basic replication is working for this table, insert a row into cluster1, check it’s there in cluster2, add a second row to cluster2 and make sure it’s visible in cluster1:
cluster1 mysql> insert into tab1 values ('Frederick', 1, 0);
cluster2 mysql> use clusterdb;
cluster2 mysql> select * from tab1;
+-----------+-------+------+
| NAME | VALUE | ts |
+-----------+-------+------+
| Frederick | 1 | 0 |
+-----------+-------+------+
1 row in set (0.00 sec)
cluster2 mysql> insert into tab1 values ('William',20,0);
cluster1 mysql> select * from tab1;
+-----------+-------+------+
| NAME | VALUE | ts |
+-----------+-------+------+
| Frederick | 1 | 0 |
| William | 20 | 0 |
+-----------+-------+------+
2 rows in set (0.00 sec)
For both rows, the timestamp was set to 0 to represent ‘the start of time’, from this point on, whenever making a change to those rows, the timestamp should be increased. Later on on in this article, I’ll show how to automate that process.
We’re now ready to test that the conflict resolution is working; to do so replication is stopped (in both directions) to increase the window for a conflict and the same tuple updated on each Cluster. Replication is then restarted and then I’ll confirm that the last update wins on both clusters:
cluster1 mysql> slave stop;
cluster2 mysql> slave stop;
cluster1 mysql> update tab1 set VALUE=10,ts=1 where NAME='Frederick';
cluster2 mysql> update tab1 set VALUE=11,ts=2 where NAME='Frederick';
cluster1 mysql> slave start;
cluster2 mysql> slave start;
cluster1 mysql> select * from tab1;
+-----------+-------+------+
| NAME | VALUE | ts |
+-----------+-------+------+
| William | 20 | 0 |
| Frederick | 11 | 2 |
+-----------+-------+------+
2 rows in set (0.00 sec)
clusrer2 mysql> select * from tab3;
+-----------+-------+------+
| NAME | VALUE | ts |
+-----------+-------+------+
| William | 20 | 0 |
| Frederick | 11 | 2 |
+-----------+-------+------+
2 rows in set (0.00 sec)
This confirms that the later update (timestamp of 2) is stored in both Clusters – conflict resolved!
Automating the timestamp column
Manually setting the timestamp value is convenient when testing that the mechanism is working as expected could be a nuisance in a production environment (for example, you would need to get the clocks of all application nodes exactly in sync wherever in the world they’re located). This section describes how that can be automated using stored procedures (note that stored procedures don’t work when using the NDB API to make changes but in that situation it should be straight-forward to provide wrapper methods that manage the timestamp field). Note that the timestamp must be an integer field (and needs a high level of precision) and so you can’t use the regular MySQL TIMESTAMP type.
This mechanism assumes that you’ve built “inttime.so” and deployed it to the hosts running the mysqld processes for each cluster (refer to the prerequisite section).
cluster1 mysql> create trigger tab1_insert before insert on tab3 for each row set NEW.ts=inttime;
cluster1 mysql> create trigger tab1_update before update on tab3 for each row set NEW.ts=inttime;
cluster1 mysql> insert into tab1 (NAME,VALUE) values ('James',10),('David',20);
cluster1 mysql> select * from tab1;
+-----------+-------+------------------+
| NAME | VALUE | ts |
+-----------+-------+------------------+
| William | 20 | 0 |
| David | 20 | 1250090500370307 |
| James | 10 | 1250090500370024 |
| Frederick | 11 | 2 |
+-----------+-------+------------------+
4 rows in set (0.00 sec)
cluster2 mysql> update tab1 set VALUE=55 where NAME='William';
cluster2 mysql> select * from tab1;
+-----------+-------+------------------+
| NAME | VALUE | ts |
+-----------+-------+------------------+
| James | 10 | 1250090500370024 |
| Frederick | 11 | 2 |
| William | 55 | 1250090607251846 |
| David | 20 | 1250090500370307 |
+-----------+-------+------------------+
4 rows in set (0.00 sec)
Setting up Conflict Detection (Same timestamp wins)
With this method, conflicts are detected and recorded but not automatically resolved. The intent is to allow the application to decide how to handle the conflict based on an understanding of what the data means.
Create the database on either cluster (replication will make sure that it appears in both Clusters):
mysql> create database clusterdb;
Before creating the application tables, set up the ndb_replication system table (again, in either Cluster):
mysql> CREATE TABLE mysql.ndb_replication ( db VARBINARY(63), table_name VARBINARY(63), server_id INT UNSIGNED, binlog_type INT UNSIGNED, conflict_fn VARBINARY(128), PRIMARY KEY USING HASH (db, table_name, server_id) ) ENGINE=NDB PARTITION BY KEY(db,table_name);
mysql> insert into mysql.ndb_replication values ('clusterdb', 'SubStatus', 7, NULL, 'NDB$OLD(ts)');
After that, you can create the application table and its associated exception table:
cluster1 mysql> use clusterdb;
cluster1 mysql> create table SubStatus$EX (server_id INT UNSIGNED,master_server_id INT UNSIGNED,master_epoch BIGINT UNSIGNED,count INT UNSIGNED,sub_id int not null,notes VARCHAR(30) DEFAULT 'To be resolved', PRIMARY KEY (server_id, master_server_id, master_epoch, count)) engine=ndb;
cluster1 mysql> create table SubStatus (sub_id int not null primary key, ActivationStatus varchar(20), ts BIGINT default 0) engine=ndb;
To test that the exception table gets filled in, add some rows to the table and then cause an update conflict (in a similar way to the conflict resolution example but after setting up the timestamp automation):
cluster1 mysql> create trigger SubStatus_insert before insert on SubStatus for each row set NEW.ts=inttime();
cluster1 mysql> insert into SubStatus (sub_id, ActivationStatus) values (1,'Active'),(2,'Deactivated');
cluster1 mysql> select * from SubStatus;
+--------+------------------+------------------+
| sub_id | ActivationStatus | ts |
+--------+------------------+------------------+
| 1 | Active | 1250094170589948 |
| 2 | Deactivated | 1250094170590250 |
+--------+------------------+------------------+
2 rows in set (0.00 sec)
cluster2 myql> use clusterdb;
cluster2 mysql> select * from SubStatus;
+--------+------------------+------------------+
| sub_id | ActivationStatus | ts |
+--------+------------------+------------------+
| 1 | Active | 1250094170589948 |
| 2 | Deactivated | 1250094170590250 |
+--------+------------------+------------------+
2 rows in set (0.00 sec)
cluster1 mysql> slave stop;
cluster2 mysql> slave stop;
...
(at this point, just go on to test as with the conflict resoultion example but in this case expect to see that the confict is not resolved but an entry is added into the conflict table).
Of course, you can always add a trigger on the conflict table and use that to spur the application into initiating its own conflict resolution algorithm.
 I recently hosted a webinar introducing MySQL Cluster and then looking into what’s new in the latest version (MySQL Cluster 7.4) in some more detail. The replay of the MySQL Cluster 7.4 webinar is now available here. Alternatively if just want to skim through the charts then scroll down.
I recently hosted a webinar introducing MySQL Cluster and then looking into what’s new in the latest version (MySQL Cluster 7.4) in some more detail. The replay of the MySQL Cluster 7.4 webinar is now available here. Alternatively if just want to skim through the charts then scroll down.