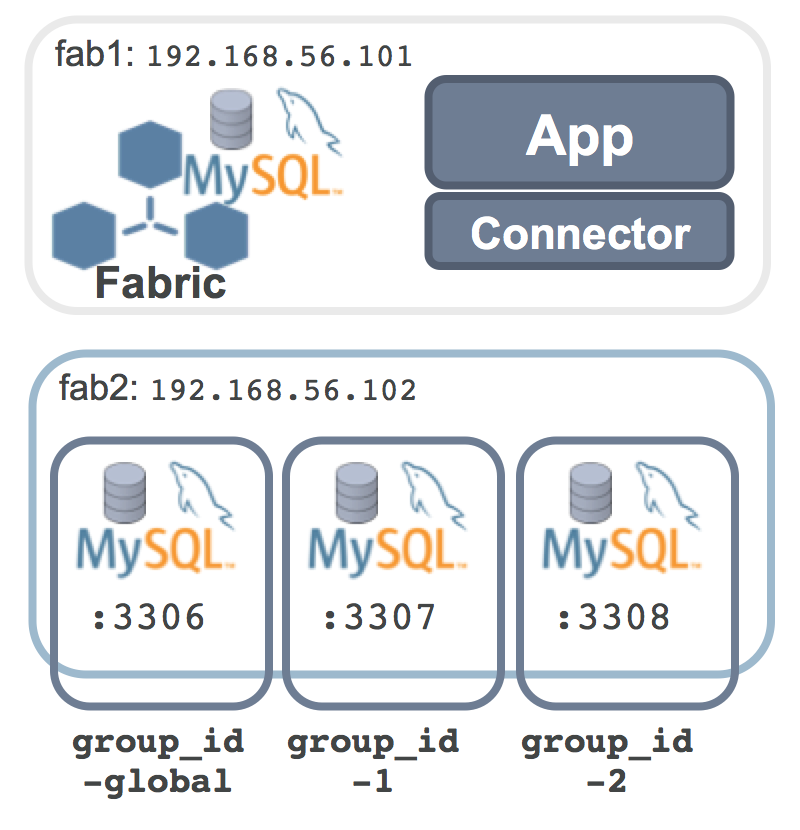
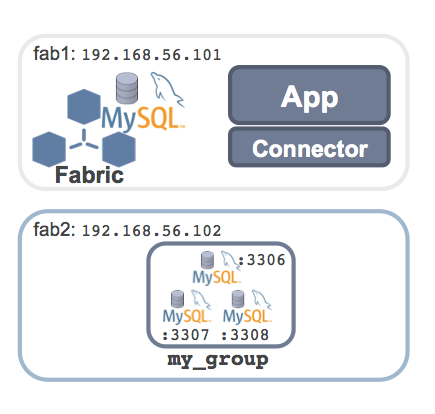
MySQL Fabric is a new framework that adds High Availability (HA) and/or scaling-out for MySQL. This is the second in a series of posts on the new MySQL Fabric framework; the first article (MySQL Fabric – adding High Availability to MySQL) explained how MySQL Fabric can deliver HA and then stepped through all of the steps to configure and use it.
This post focuses on using MySQL Fabric to scale out both reads and writes across multiple MySQL Servers. It starts with an introduction to scaling out (by partitioning/sharding data) and how MySQL Fabric achieves it before going on to work through a full example of configuring sharding across a farm of MySQL Servers together with the code that the application developer needs to write in order to exploit it. Note that at the time of writing, MySQL Fabric is not yet GA but is available as a public alpha.
Scaling Out – Sharding
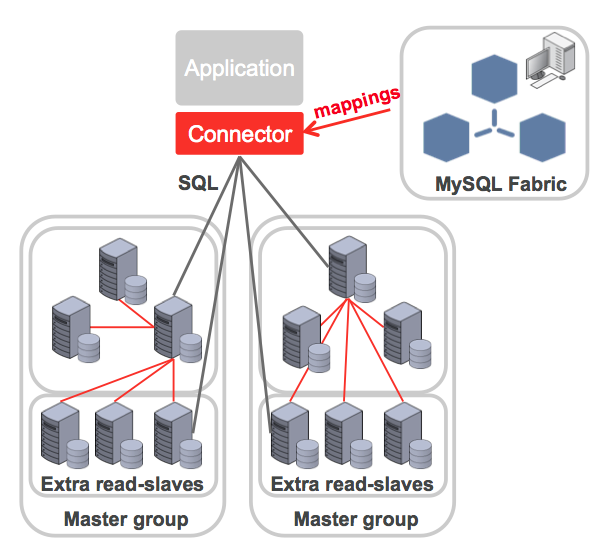
When nearing the capacity or write performance limit of a single MySQL Server (or HA group), MySQL Fabric can be used to scale-out the database servers by partitioning the data across multiple MySQL Server “groups”. Note that a group could contain a single MySQL Server or it could be a HA group.
The administrator defines how data should be partitioned/sharded between these servers; this is done by creating shard mappings. A shard mapping applies to a set of tables and for each table the administrator specifies which column from those tables should be used as a shard key (the shard key will subsequently be used by MySQL Fabric to calculate which shard a specific row from one of those tables should be part of). Because all of these tables use the same shard key and mapping, the use of the same column value in those tables will result in those rows being in the same shard – allowing a single transaction to access all of them. For example, if using the subscriber-id column from multiple tables then all of the data for a specific subscriber will be in the same shard. The administrator then defines how that shard key should be used to calculate the shard number:
- HASH: A hash function is run on the shard key to generate the shard number. If values held in the column used as the sharding key don’t tend to have too many repeated values then this should result in an even partitioning of rows across the shards.
- RANGE: The administrator defines an explicit mapping between ranges of values for the sharding key and shards. This gives maximum control to the user of how data is partitioned and which rows should be co-located.
When the application needs to access the sharded database, it sets a property for the connection that specifies the sharding key – the Fabric-aware connector will then apply the correct range or hash mapping and route the transaction to the correct shard.
If further shards/groups are needed then MySQL Fabric can split an existing shard into two and then update the state-store and the caches of routing data held by the connectors. Similarly, a shard can be moved from one HA group to another.
Note that a single transaction or query can only access a single shard and so it is important to select shard keys based on an understanding of the data and the application’s access patterns. It doesn’t always make sense to shard all tables as some may be relatively small and having their full contents available in each group can be beneficial given the rule about no cross-shard queries. These global tables are written to a ‘global group’ and any additions or changes to data in those tables are automatically replicated to all of the other groups. Schema changes are also made to the global group and replicated to all of the others to ensure consistency.
To get the best mapping, it may also be necessary to modify the schema if there isn’t already a ‘natural choice’ for the sharding keys.
Worked Example
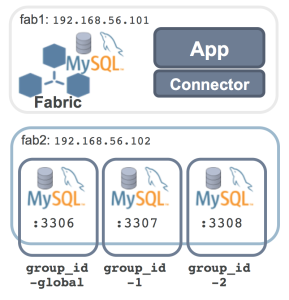
The following steps set up the sharded MySQL configuration shown here before running some (Python) code against – with queries and transactions routed to the correct MySQL Server.
Building the Sharded MySQL Server Farm
The machines being used already have MySQL 5.6 installed (though in a custom location) and so the only software pre-requisite is to install the MySQL connector for Python from the “Development Releases” tab from the connector download page and MySQL Fabric (part of MySQL Utilities) from the “Development Releases” tab on the MySQL Utilities download page:
[root@fab1 mysql ~]# rpm -i mysql-connector-python-1.2.0-1.el6.noarch.rpm
[root@fab1 mysql ~]# rpm -i mysql-utilities-1.4.1-1.el6.noarch.rpm
MySQL Fabric needs access to a MySQL Database to store state and routing information for the farm of servers; if there isn’t already a running MySQL Server instance that can be used for this then it’s simple to set one up:
[mysql@fab1 ~]$ mkdir myfab
[mysql@fab1 ~]$ cd myfab/
[mysql@fab1 myfab]$ mkdir data
[mysql@fab1 myfab]$ cat my.cnf
[mysqld]
datadir=/home/mysql/myfab/data
basedir=/home/mysql/mysql
socket=/home/mysql/myfab/mysqlfab.socket
binlog-format=ROW
log-slave-updates=true
gtid-mode=on
enforce-gtid-consistency=true
master-info-repository=TABLE
relay-log-info-repository=TABLE
sync-master-info=1
port=3306
report-host=fab1
report-port=3306
server-id=1
log-bin=fab-bin.log
[mysql@fab1 mysql]$ scripts/mysql_install_db --basedir=/home/mysql/mysql/ \
--datadir=/home/mysql/myfab/data/
2014-02-12 16:55:45 1298 [Note] Binlog end
2014-02-12 16:55:45 1298 [Note] InnoDB: FTS optimize thread exiting.
2014-02-12 16:55:45 1298 [Note] InnoDB: Starting shutdown...
2014-02-12 16:55:46 1298 [Note] InnoDB: Shutdown completed; log sequence number 1600607
2014-02-12 16:55:46 1298 [Note] /home/mysql/mysql//bin/mysqld: Shutdown complete
[mysql@fab1 ~]$ mysqld --defaults-file=/home/mysql/myfab/my.cnf &
MySQL Fabric needs to be able to access this state store and so a dedicated user is created (note that the fabric database hasn’t yet been created – that will be done soon using the mysqlfabric command):
[mysql@fab1 ~]$ mysql -h 127.0.0.1 -P3306 -u root -e "GRANT ALL ON fabric.* \
TO fabric@localhost";
All of the management requests that we make for MySQL Fabric will be issued via the mysqlfabric command. This command is documented in the MySQL Fabric User Guide but sub-commands can be viewed from the terminal using the list-commands option:
[mysql@fab1 /]$ mysqlfabric list-commands
group activate Activate a group.
group import_topology Try to figure out the replication topology
and import it into the state store.
group deactivate Deactivate a group.
group create Create a group.
group remove Remove a server from a group.
group add Add a server into group.
group lookup_servers Return information on existing server(s) in a
group.
group check_group_availability Check if any server within a group has failed
and report health information.
group destroy Remove a group.
group demote Demote the current master if there is one.
group promote Promote a server into master.
group lookup_groups Return information on existing group(s).
group description Update group's description.
manage list-commands List the possible commands.
manage help Give help on a command.
manage teardown Teardown Fabric Storage System.
manage stop Stop the Fabric server.
manage setup Setup Fabric Storage System.
manage ping Check whether Fabric server is running or not.
manage start Start the Fabric server.
manage logging_level Set logging level.
server set_weight Set a server's weight which determines the
likelihood of a server being chosen by a
connector to process transactions or by the
high availability service to replace a failed
master.
server lookup_uuid Return server's uuid.
server set_mode Set a server's mode which determines whether
it can process read-only, read-write or both
transaction types.
server set_status Set a server's status.
sharding move Move the shard represented by the shard_id to
the destination group.
sharding lookup_servers Lookup a shard based on the give sharding key.
sharding disable_shard Disable a shard.
sharding remove_mapping Remove the shard mapping represented by the
Shard Mapping object.
sharding list_mappings Returns all the shard mappings of a
particular sharding_type.
sharding add_mapping Add a table to a shard mapping.
sharding add_shard Add a shard.
sharding list_definitions Lists all the shard mapping definitions.
sharding enable_shard Enable a shard.
sharding remove_shard Remove a Shard.
sharding prune_shard Given the table name prune the tables
according to the defined sharding
specification for the table.
sharding lookup_mapping Fetch the shard specification mapping for the
given table
sharding split Split the shard represented by the shard_id
into the destination group.
sharding define Define a shard mapping.
event trigger Trigger an event.
event wait_for_procedures Wait until procedures, which are identified
through their uuid in a list and separated by
comma, finish their execution.
store dump_shard_maps Return information about all shard mappings
matching any of the provided patterns.
store dump_shard_index Return information about the index for all
mappings matching any of the patterns
provided.
store dump_servers Return information about all servers.
store dump_sharding_information Return all the sharding information about the
tables passed as patterns.
store dump_shard_tables Return information about all tables belonging
to mappings matching any of the provided
patterns.
store lookup_fabrics Return a list of Fabric servers.
MySQL Fabric has its own configuration file (note that it’s location can vary depending on your platform and how MySQL Utilities were installed). The contents of this configuration file should be reviewed before starting the MySQL Fabric process (in this case, the mysqldump_program and mysqldump_program settings needed to be changed as MySQL was installed in a user’s directory):
[root@fab1 mysql]# cat /etc/mysql/fabric.cfg
[DEFAULT]
prefix =
sysconfdir = /etc/mysql
logdir = /var/log
[logging]
url = file:///var/log/fabric.log
level = INFO
[storage]
database = fabric
user = fabric
address = localhost:3306
connection_delay = 1
connection_timeout = 6
password =
connection_attempts = 6
[connector]
ttl = 1
[protocol.xmlrpc]
threads = 5
address = localhost:8080
[executor]
executors = 5
[sharding]
mysqldump_program = /home/mysql/mysql/bin/mysqldump
mysqlclient_program = /home/mysql/mysql/bin/mysql
The final step before starting the MySQL Fabric process is to create the MySQL Fabric schema within the state store:
[mysql@fab1 ~]$ mysqlfabric manage setup --param=storage.user=fabric
[INFO] 1392298030.100127 - MainThread - Initializing persister: \
user (fabric), server (localhost:3306), database (fabric).
An optional step is then to check for yourself that the schema is indeed there:
[mysql@fab1 ~]$ mysql --protocol=tcp -u root
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 5
Server version: 5.6.16-log MySQL Community Server (GPL)
Copyright (c) 2000, 2014, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| fabric |
| mysql |
| performance_schema |
| test |
+--------------------+
5 rows in set (0.00 sec)
mysql> use fabric;show tables;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
+-------------------+
| Tables_in_fabric |
+-------------------+
| checkpoints |
| group_replication |
| groups |
| servers |
| shard_maps |
| shard_ranges |
| shard_tables |
| shards |
+-------------------+
8 rows in set (0.00 sec)
The MySQL Fabric process can now be started; in this case the process will run from the terminal from which it’s started but the --daemonize option can be used to make it run as a daemon.
[mysql@fab1 ~]$ mysqlfabric manage start
[INFO] 1392298245.888881 - MainThread - Fabric node starting.
[INFO] 1392298245.890465 - MainThread - Initializing persister: user (fabric), server (localhost:3306), database (fabric).
[INFO] 1392298245.890926 - MainThread - Loading Services.
[INFO] 1392298245.898459 - MainThread - Starting Executor.
[INFO] 1392298245.899056 - MainThread - Setting 5 executor(s).
[INFO] 1392298245.900439 - Executor-1 - Started.
[INFO] 1392298245.901856 - Executor-2 - Started.
[INFO] 1392298245.903146 - Executor-0 - Started.
[INFO] 1392298245.905488 - Executor-3 - Started.
[INFO] 1392298245.908283 - MainThread - Executor started.
[INFO] 1392298245.910308 - Executor-4 - Started.
[INFO] 1392298245.936954 - MainThread - Starting failure detector.
[INFO] 1392298245.938200 - XML-RPC-Server - XML-RPC protocol server \
('127.0.0.1', 8080) started.
[INFO] 1392298245.938614 - XML-RPC-Server - Setting 5 XML-RPC session(s).
[INFO] 1392298245.940895 - XML-RPC-Session-0 - Started XML-RPC-Session.
[INFO] 1392298245.942644 - XML-RPC-Session-1 - Started XML-RPC-Session.
[INFO] 1392298245.947016 - XML-RPC-Session-2 - Started XML-RPC-Session.
[INFO] 1392298245.949691 - XML-RPC-Session-3 - Started XML-RPC-Session.
[INFO] 1392298245.951678 - XML-RPC-Session-4 - Started XML-RPC-Session.
If the process had been run as a daemon then it’s useful to be able to check if it’s actually running:
[mysql@fab1 ~]$ mysqlfabric manage ping
Command :
{ success = True
return = True
activities =
}
At this point, MySQL Fabric is up and running but it has no MySQL Servers to manage. As shown in the earlier diagram, three MySQL Servers will run on a single machine. Each of those MySQL Servers will need their own configuration settings to make sure that there are no resource conflicts – the steps are shown here but without any detailed commentary as this is standard MySQL stuff:
[mysql@fab2 myfab]$ cat my1a.cnf
[mysqld]
datadir=/home/mysql/myfab/data1a
basedir=/home/mysql/mysql
socket=/home/mysql/myfab/mysqlfab1a.socket
binlog-format=ROW
log-slave-updates=true
gtid-mode=on
enforce-gtid-consistency=true
master-info-repository=TABLE
relay-log-info-repository=TABLE
sync-master-info=1
port=3306
report-host=fab2
report-port=3306
server-id=11
log-bin=fab1a-bin.log
[mysql@fab2 myfab]$ cat my1b.cnf
[mysqld]
datadir=/home/mysql/myfab/data1b
basedir=/home/mysql/mysql
socket=/home/mysql/myfab/mysqlfab1b.socket
binlog-format=ROW
log-slave-updates=true
gtid-mode=on
enforce-gtid-consistency=true
master-info-repository=TABLE
relay-log-info-repository=TABLE
sync-master-info=1
port=3307
report-host=fab2
report-port=3307
server-id=12
log-bin=fab1b-bin.log
[mysql@fab2 myfab]$ cat my1c.cnf
[mysqld]
datadir=/home/mysql/myfab/data1c
basedir=/home/mysql/mysql
socket=/home/mysql/myfab/mysqlfab1c.socket
binlog-format=ROW
log-slave-updates=true
gtid-mode=on
enforce-gtid-consistency=true
master-info-repository=TABLE
relay-log-info-repository=TABLE
sync-master-info=1
port=3308
report-host=fab2
report-port=3308
server-id=13
log-bin=fab1c-bin.log
[mysql@fab2 myfab]$ mkdir data1a
[mysql@fab2 myfab]$ mkdir data1b
[mysql@fab2 myfab]$ mkdir data1c
[mysql@fab2 mysql]$ scripts/mysql_install_db --basedir=/home/mysql/mysql/ \
--defaults-file=/home/mysql/myfab/my1a.cnf \
--datadir=/home/mysql/myfab/data1a/
[mysql@fab2 mysql]$ scripts/mysql_install_db --basedir=/home/mysql/mysql/ \
--defaults-file=/home/mysql/myfab/my1a.cnf \
--datadir=/home/mysql/myfab/data1b/
[mysql@fab2 mysql]$ scripts/mysql_install_db --basedir=/home/mysql/mysql/ \
--defaults-file=/home/mysql/myfab/my1a.cnf \
--datadir=/home/mysql/myfab/data1c/
[mysql@fab2 ~]$ mysqld --defaults-file=/home/mysql/myfab/my1a.cnf &
[mysql@fab2 ~]$ mysqld --defaults-file=/home/mysql/myfab/my1b.cnf &
[mysql@fab2 ~]$ mysqld --defaults-file=/home/mysql/myfab/my1c.cnf &
[mysql@fab2 ~]$ mysql -h 127.0.0.1 -P3306 -u root -e "GRANT ALL ON *.* \
TO root@'%'""
[mysql@fab2 ~]$ mysql -h 127.0.0.1 -P3307 -u root -e "GRANT ALL ON *.* \
TO root@'%'""
[mysql@fab2 ~]$ mysql -h 127.0.0.1 -P3308 -u root -e "GRANT ALL ON *.* \
TO root@'%'""
At this point, the MySQL Fabric process (and its associate state store) is up and running, as are the MySQL Servers that will become part of the Fabric server farm. The next step is to define the groups (and assign a server to each one); the mappings that will be used to map from shard keys to shards and then finally the shards themselves.
The first group that’s created is the global group group_id-global which is where all changes to the data schema or to the global tables (those tables that are duplicated in every group rather than being sharded) are sent and then replicated to all of the other groups.
[mysql@fab1 ~]$ mysqlfabric group create group_id-global
Procedure :
{ uuid = 721888b2-f604-4001-94c9-5911e1a198b3,
finished = True,
success = True,
return = True,
activities =
}
After that, the two groups that will contain the sharded table data are created – group_id-1&group_id-2.
[mysql@fab1 ~]$ mysqlfabric group create group_id-1
Procedure :
{ uuid = 02f0a99d-5444-4f5b-b5df-b500de5a2d96,
finished = True,
success = True,
return = True,
activities =
}
[mysql@fab1 ~]$ mysqlfabric group create group_id-2
Procedure :
{ uuid = fb8c3638-7b2b-4106-baac-3531a4606792,
finished = True,
success = True,
return = True,
activities =
}
The three groups have now been created but they’re all empty and so the next step is to assign a single MySQL Server to each one.
[mysql@fab1 ~]$ mysqlfabric group add group_id-global 192.168.56.102:3306 root ""
Procedure :
{ uuid = 9d851625-f488-4e9a-b18f-bfb952a18be6,
finished = True,
success = True,
return = True,
activities =
}
[mysql@fab1 ~]$ mysqlfabric group add group_id-1 192.168.56.102:3307 root ""
Procedure :
{ uuid = 1e0230ce-2309-4a11-92a4-4bf9f11061c3,
finished = True,
success = True,
return = True,
activities =
}
[mysql@fab1 ~]$ mysqlfabric group add group_id-2 192.168.56.102:3308 root ""
Procedure :
{ uuid = cf5cd7ae-cf47-4c10-b68d-867fbff3c597,
finished = True,
success = True,
return = True,
activities =
}
Optionally, the mysqlfabric command can then be used to confirm this configuration.
[mysql@fab1 ~]$ mysqlfabric group lookup_groups
Command :
{ success = True
return = [['group_id-1'], ['group_id-2'], ['group_id-global']]
activities =
}
[mysql@fab1 ~]$ mysqlfabric group lookup_servers group_id-global
Command :
{ success = True
return = [['57dc7afc-957d-11e3-91a8-08002795076a', \
'192.168.56.102', False, 'SECONDARY']]
activities =
}
[mysql@fab1 ~]$ mysqlfabric group lookup_servers group_id-1
Command :
{ success = True
return = [['9c08ecd6-94b9-11e3-8cab-08002795076a', \
'192.168.56.102:3307', False, 'SECONDARY']]
activities =
}
[mysql@fab1 ~]$ mysqlfabric group lookup_servers group_id-2
Command :
{ success = True
return = [['a4a963a1-94b9-11e3-8cac-08002795076a', \
'192.168.56.102:3308', False, 'SECONDARY']]
activities =
}
Even though each of these groups contains a single server, it’s still necessary to promote those servers to be Primaries so that the Fabric-aware connectors will send writes to them.
[mysql@fab1 ~]$ mysqlfabric group promote group_id-global
Procedure :
{ uuid = fd29b5f9-97dc-4189-a7df-2d98b230a124,
finished = True,
success = True,
return = True,
activities =
}
[mysql@fab1 ~]$ mysqlfabric group promote group_id-1
Procedure :
{ uuid = a00e1a42-3a07-4539-a86b-1f9ac8284d27,
finished = True,
success = True,
return = True,
activities =
}
[mysql@fab1 ~]$ mysqlfabric group promote group_id-2
Procedure :
{ uuid = 32663313-8b6d-427b-8516-87539d712606,
finished = True,
success = True,
return = True,
activities =
}
[mysql@fab1 ~]$ mysqlfabric group lookup_servers group_id-1
Command :
{ success = True
return = [['9c08ecd6-94b9-11e3-8cab-08002795076a', \
'192.168.56.102:3307', True, 'PRIMARY']]
activities =
}
[mysql@fab1 ~]$ mysqlfabric group lookup_servers group_id-2
Command :
{ success = True
return = [['a4a963a1-94b9-11e3-8cac-08002795076a', \
'192.168.56.102:3308', True, 'PRIMARY']]
activities =
}
[mysql@fab1 ~]$ mysqlfabric group lookup_servers group_id-global
Command :
{ success = True
return = [['57dc7afc-957d-11e3-91a8-08002795076a', \
'192.168.56.102', True, 'PRIMARY']]
activities =
}
Shard mappings are used to map shard keys to shards and they can be based on ranges or on a hash of the shard key – in this example, a single mapping will be created and it will be based on ranges. When creating the shard mapping, the name of the global group must be supplied – in this case group_id-global.
[mysql@fab1 ~]$ mysqlfabric sharding define RANGE group_id-global
Procedure :
{ uuid = d201b476-6ca2-4fd9-a3b2-619552b5fcd2,
finished = True,
success = True,
return = 1,
activities =
}
From the return code, you can observe that the ID given to the shard mapping is 1 – that can optionally be confirmed by checking the meta data in the state store:
[mysql@fab1 ~]$ mysql --protocol=tcp -ufabric -e \
"SELECT * FROM test.shard_maps"
+------------------+-----------+-----------------+
| shard_mapping_id | type_name | global_group |
+------------------+-----------+-----------------+
| 1 | RANGE | group_id-global |
+------------------+-----------+-----------------+
The next step is to define the sharding key for each of the tables that we want to be partitioned as part of this mapping. In fact, this example is only sharding one table test.subscribers but the command can be repeated for multiple tables. The name of the column to be used as the sharding key must also be supplied (in this case sub_no) as must the ID for the shard mapping (which we’ve just confirmed is 1).
[mysql@fab1 myfab]$ mysqlfabric sharding add_mapping 1 test.subscribers sub_no
Procedure :
{ uuid = 5ae7fe49-2c99-42d2-890a-8ee00c142719,
finished = True,
success = True,
return = True,
activities =
}
Again, the state store can be checked to confirm that this has been set up correctly.
[mysql@fab1 ~]$ mysql --protocol=tcp -ufabric -e \
"SELECT * FROM test.shard_tables"
+------------------+------------------+-------------+
| shard_mapping_id | table_name | column_name |
+------------------+------------------+-------------+
| 1 | test.subscribers | sub_no |
+------------------+------------------+-------------+
The next step is to define the shards themselves. In this example, all values of sub_no from 1-9999 will be mapped to the first shard (which will be associated with group_id-1) and from 10000 and up to the second shard (group_id-2). Again the shard mapping ID (1) must also be provided.
[mysql@fab1 ~]$ mysqlfabric sharding add_shard 1 group_id-1 ENABLED 1
Procedure :
{ uuid = 21b5c976-31ab-432b-8bf3-f19a84b2ed47,
finished = True,
success = True,
return = True,
activities =
}
[mysql@fab1 ~]$ mysqlfabric sharding add_shard 1 group_id-2 ENABLED 10000
Procedure :
{ uuid = f837bded-825c-46a5-8edb-fe4557c53417,
finished = True,
success = True,
return = True,
activities =
}
Example Application Code
Now that the MySQL Fabric farm is up and running we can start running some code against it. There are currently Fabric-aware connectors for PHP, Python and Java – for this post, Python is used.
Note that while they must make some minor changes to work with the sharded database, they don’t need to care about what servers are part of the farm, what shards exist or where they’re located – this is all handled by MySQL Fabric and the Fabric-aware connectors. What they do need to do is provide the hints needed by the connector to figure out where to send the query or transaction.
The first piece of example code will create the subscribers table within the test database. Most of this is fairly standard and so only the MySQL Fabric-specific pieces will be commented on:
- The
fabric module from mysql.com is included
- The application connects to MySQL Fabric rather than any of the MySQL Servers (
{"host" : "localhost", "port" : 8080})
- The
scope property for the connection is set to fabric.SCOPE_GLOBAL – in that way the operations are sent to the global group by the connector so that the schema changes will be replicated to all servers in the HA group (the same would be true if writing to a non-sharded (global) table).
[mysql@fab1 myfab]$ cat setup_table_shards.py
import mysql.connector
from mysql.connector import fabric
conn = mysql.connector.connect(
fabric={"host" : "localhost", "port" : 8080},
user="root", database="test", password="",
autocommit=True
)
conn.set_property(tables=["test.subscribers"], scope=fabric.SCOPE_GLOBAL)
cur = conn.cursor()
cur.execute(
"CREATE TABLE IF NOT EXISTS subscribers ("
" sub_no INT, "
" first_name CHAR(40), "
" last_name CHAR(40)"
")"
)
The code can then be executed:
[mysql@fab1 myfab]$ python setup_table_shards.py
The next piece of application code adds some records to the test.subscribers table. To ensure that the connector can route the transactions to the correct group, the following properties are set for the connection: scope is set to fabric.SCOPE_LOCAL (i.e. not global); tables is set to "test.subscribers" which allows the connector to select the correct mapping and key is set to the value of the sub_no being used for the row in the current transaction so that the connector can perform a range test on it to find the correct shard. The mode property is also set to fabric.MODE_READWRITE (if [HA groups]:(http://www.clusterdb.com/mysql-fabric/mysql-fabric-adding-high-availability-to-mysql “MySQL Fabric – adding High Availability to MySQL”) were being used then this would tell the connector to send the transaction to the primary).
[mysql@fab1 myfab]$ cat add_subs_shards.py
import mysql.connector
from mysql.connector import fabric
def add_subscriber(conn, sub_no, first_name, last_name):
conn.set_property(tables=["test.subscribers"], key=sub_no, \
mode=fabric.MODE_READWRITE)
cur = conn.cursor()
cur.execute(
"REPLACE INTO subscribers VALUES (%s, %s, %s)",
(sub_no, first_name, last_name)
)
# Address of the Fabric node, rather than the actual MySQL Server.
conn = mysql.connector.connect(
fabric={"host" : "localhost", "port" : 8080},
user="root", database="test", password="",
autocommit=True
)
conn.set_property(tables=["test.subscribers"], scope=fabric.SCOPE_LOCAL)
add_subscriber(conn, 72, "Billy", "Fish")
add_subscriber(conn, 500, "Billy", "Joel")
add_subscriber(conn, 1500, "Arthur", "Askey")
add_subscriber(conn, 5000, "Billy", "Fish")
add_subscriber(conn, 15000, "Jimmy", "White")
add_subscriber(conn, 17542, "Bobby", "Ball")
This application code is then run and then the servers from each of the groups queried to confirm that the data has been sharded as expected (based on the 0-9999 and 10000+ range definition).
[mysql@fab1 myfab]$ python add_subs_shards.py
[mysql@fab1 myfab]$ mysql -h 192.168.56.102 -P3307 -uroot –e 'SELECT * \
FROM test.subscribers'
+--------+------------+-----------+
| sub_no | first_name | last_name |
+--------+------------+-----------+
| 72 | Billy | Fish |
| 500 | Billy | Joel |
| 1500 | Arthur | Askey |
| 5000 | Billy | Fish |
+--------+------------+-----------+
[mysql@fab1 myfab]$ mysql -h 192.168.56.102 -P3308 -uroot -e 'SELECT * \
FROM test.subscribers'
+--------+------------+-----------+
| sub_no | first_name | last_name |
+--------+------------+-----------+
| 15000 | Jimmy | White |
| 17542 | Bobby | Ball |
+--------+------------+-----------+
The final piece of application code reads back the rows. Note that in this case the connection’s mode property is set to fabric.READONLY which tells the connector that if [HA groups]:(http://www.clusterdb.com/mysql-fabric/mysql-fabric-adding-high-availability-to-mysql “MySQL Fabric – adding High Availability to MySQL”) were being used then the queries could be sent to any of the Secondaries.
[mysql@fab1 myfab]$ cat read_table_shards.py
import mysql.connector
from mysql.connector import fabric
def find_subscriber(conn, sub_no):
conn.set_property(tables=["test.subscribers"], key=sub_no, \
mode=fabric.MODE_READONLY)
cur = conn.cursor()
cur.execute(
"SELECT first_name, last_name FROM subscribers "
"WHERE sub_no = %s", (sub_no, )
)
for row in cur:
print rows
conn = mysql.connector.connect(
fabric={"host" : "localhost", "port" : 8080},
user="root", database="test", password="",
autocommit=True
)
find_subscriber(conn, 72)
find_subscriber(conn, 500)
find_subscriber(conn, 1500)
find_subscriber(conn, 5000)
find_subscriber(conn, 15000)
find_subscriber(conn, 17542)
[mysql@fab1 myfab]$ python read_table_shards.py
(u'Billy', u'Fish')
(u'Billy', u'Joel')
(u'Arthur', u'Askey')
(u'Billy', u'Fish')
(u'Jimmy', u'White')
(u'Bobby', u'Ball')
MySQL Fabric Architecture & Extensibility
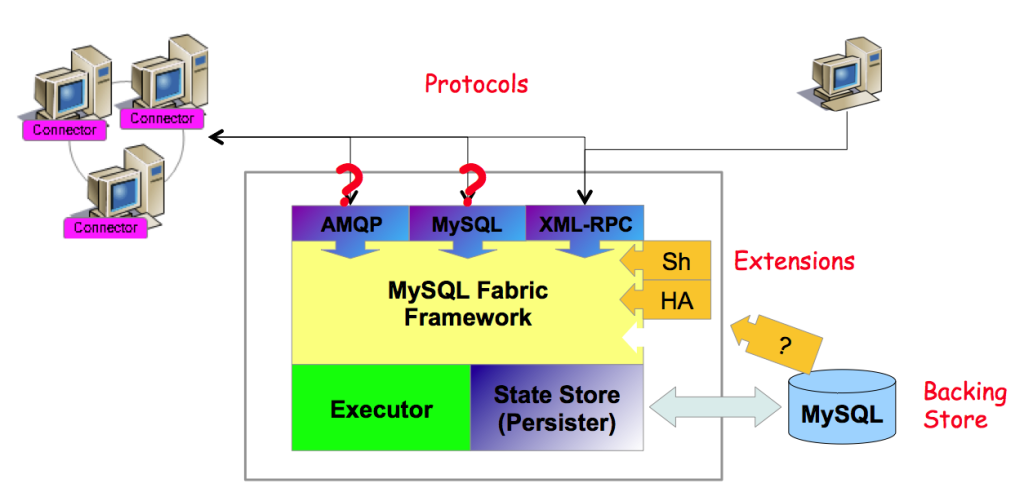
MySQL Fabric has been architected for extensibility at a number of levels. For example, in the first release the only option for implementing HA is based on MySQL Replication but in future releases we hope to add further options (for example, MySQL Cluster). We also hope to see completely new applications around the managing of farms of MySQL Servers – both from Oracle and the wider MySQL community.
The following diagram illustrates how new applications and protocols can be added using the pluggable framework.
Next Steps
We really hope that people try out MySQL Fabric and let us know how you get on; one way is to comment on this post, another is to post to the MySQL Fabric forum or if you think you’ve found a bug then raise a bug report.
 The first version of MySQL Cluster 7.4 has now been released on MySQL Labs. Note that labs loads are not suitable for production use (in fact they’re even less mature than Development Milestone Releases); their purpose is to give users a chance to see what’s in the works, try it for themselves and then provide feedback. Having read that, if you’d like to try it out then Download MySQL Cluster 7.4 from MySQL Labs.
The first version of MySQL Cluster 7.4 has now been released on MySQL Labs. Note that labs loads are not suitable for production use (in fact they’re even less mature than Development Milestone Releases); their purpose is to give users a chance to see what’s in the works, try it for themselves and then provide feedback. Having read that, if you’d like to try it out then Download MySQL Cluster 7.4 from MySQL Labs.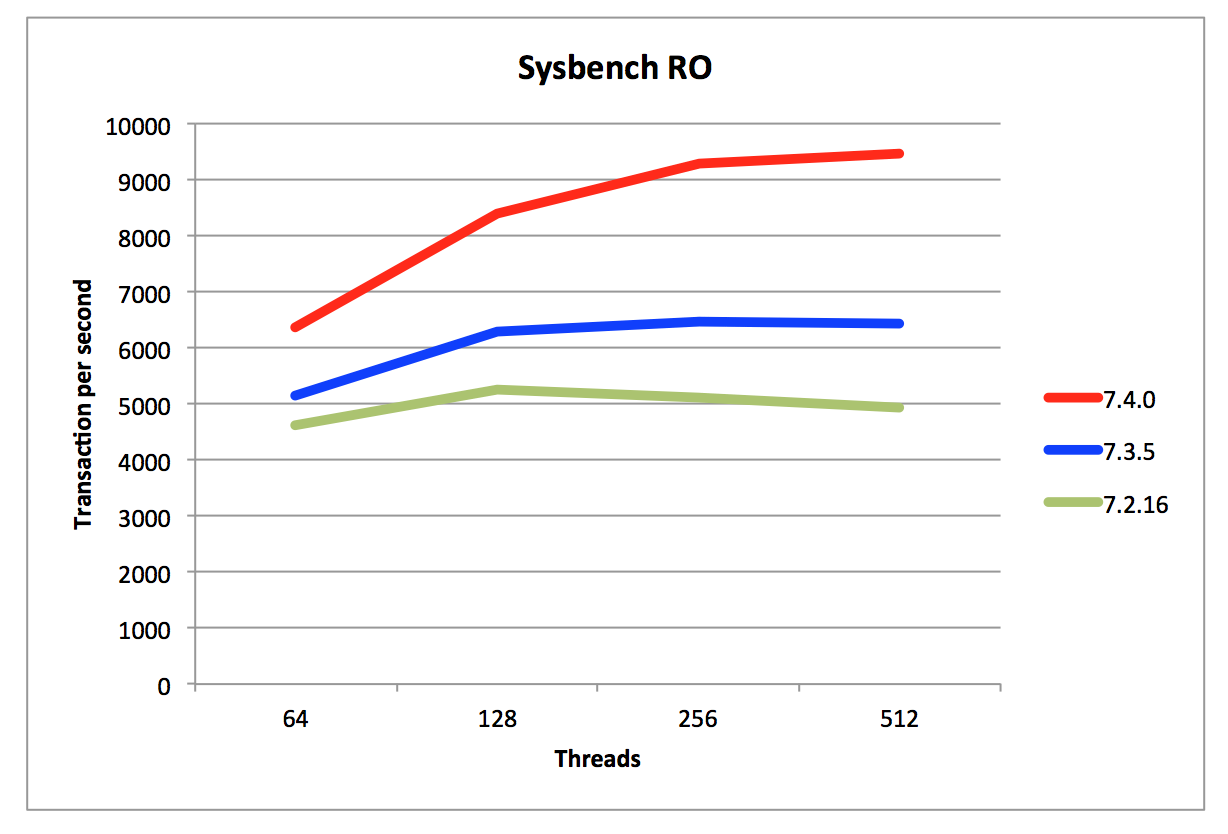 MySQL Cluster was designed from the outset to be a distributed, in-memory database and has been deployed that way for many, many years (it’s interesting to see that the idea of in-memory databases has now really come into vogue with excitement around new arrivals on the scene such as Hekaton). Not surprisingly when people are considering MySQL Cluster, performance and scalability are key features (High Availability is another) and so performance improvements are always a key focus of every release and MySQL CLuster 7.4 is no exception.
MySQL Cluster was designed from the outset to be a distributed, in-memory database and has been deployed that way for many, many years (it’s interesting to see that the idea of in-memory databases has now really come into vogue with excitement around new arrivals on the scene such as Hekaton). Not surprisingly when people are considering MySQL Cluster, performance and scalability are key features (High Availability is another) and so performance improvements are always a key focus of every release and MySQL CLuster 7.4 is no exception. The graphs show what’s already been acheived with Read Only Sysbench showing a 47% increase in throughput and a 38% improvement for the Read/Write benchmark. Even better improvements are seen when configuring the data nodes to use even more threads. For those not familiar with Sysbench, you should realise that each of the transactions involves quite a lot of work: 10 Primary Key lookups, 5 different types of scans where we fetch 100 records (normal select through ordered index followed by oder by, group by and so forth).
The graphs show what’s already been acheived with Read Only Sysbench showing a 47% increase in throughput and a 38% improvement for the Read/Write benchmark. Even better improvements are seen when configuring the data nodes to use even more threads. For those not familiar with Sysbench, you should realise that each of the transactions involves quite a lot of work: 10 Primary Key lookups, 5 different types of scans where we fetch 100 records (normal select through ordered index followed by oder by, group by and so forth).