Adding Document Validation Rules Using MongoDB Compass 1.5
This post looks at a new feature in MongoDB Compass 1.5 (in beta at the time of writing) which allows document validation rules to be added from the GUI rather from the mongo shell command line. This makes it easy to create and modify rules that ensure that all documents written to a collection contain the data you expect to be there.
Introduction
One of MongoDB’s primary attractions for developers is that it gives them the ability to start application development without first needing to define a formal schema. Operations teams appreciate the fact that they don’t need to perform a time-consuming schema upgrade operation every time the developers need to store a different attribute. For business leaders, the application gets launched much faster, and new features can be rolled out more frequently. MongoDB powers agility.
Many projects reach a point where it’s necessary to enforce rules on what’s being stored in the database – for example, that for any document in a particular collection, you can be certain that specific attributes are present in every document. Reasons for this include:
- Different development teams can work with the same data, each needing to know what they can expect to find in a particular collection.
- Development teams working on different applications can be spread over multiple sites, which means that a clear agreement on the format of shared data is important.
- Development teams from different companies may be working with the same collections; misunderstandings about what data should be present can lead to issues.
As an example, an e-commerce website may centralize product catalog feeds from multiple vendors into a single collection. If one of the vendors alters the format of its product catalog, global catalog searches could fail.
To date, this resulted in developers building their own validation logic – either within the application code (possibly multiple times for different applications) or by adding middleware such as Mongoose.
To address the challenges discussed above, while at the same time maintaining the benefits of a dynamic schema, MongoDB 3.2 introduced document validations. Adding and viewing validation rules required understanding the correct commands to run from the mongo shell’s command line.
MongoDB Compass 1.5 allows users to view, add, and modify document validation rules through its GUI, making them more accessible to both developers and DBAs.
Validating Documents in MongoDB
Document Validation provides significant flexibility to customize which parts of the documents are and are not validated for any collection. For any attribute it might be appropriate to check:
- That the attribute exists
- If an attribute does exist, that it is of the correct type
- That the value is in a particular format (e.g., regular expressions can be used to check if the contents of the string matches a particular pattern)
- That the value falls within a given range
Further, it may be necessary to combine these checks – for example that the document contains the user’s name and either their email address or phone number, and if the email address does exist, then it must be correctly formed.
Adding the validation checks from the command line is intuitive to developers or DBAs familiar with the MongoDB query language as it uses the same expression syntax as a find query to search the database. For others, it can be a little intimidating.
As an example, the following snippet adds validations to the contacts collection that validates:
- The year of birth is no later than 1994
- The document contains a phone number and/or an email address
- When present, the phone number and email address are strings
db.runCommand({
collMod: "contacts",
validator: {
$and: [
{yearOfBirth: {$lte: 1994}},
{$or: [
{"contact.phone": { $type: "string"}},
{"email": { $type: "string"}}
]}]
}})
Note that types can be specified using either a number or a string alias.
Wouldn’t it be nice to be able to define these rules through a GUI rather than from the command line?
Using MongoDB Compass to Add Document Validation Rules
If you don’t already have MongoDB Compass 1.5 (or later) installed, download it and start the application. You’ll then be asked to provide details on how to connect to your database.
MongoDB Compass is free for evaluation and for use in development, for production, a MongoDB Professional of MongoDB Enterprise Advanced subscription is required.
If you don’t have a database to test this on, the simplest option is to create a new MongoDB Atlas cluster. Details on launching a MongoDB Atlas cluster can be found in this post.
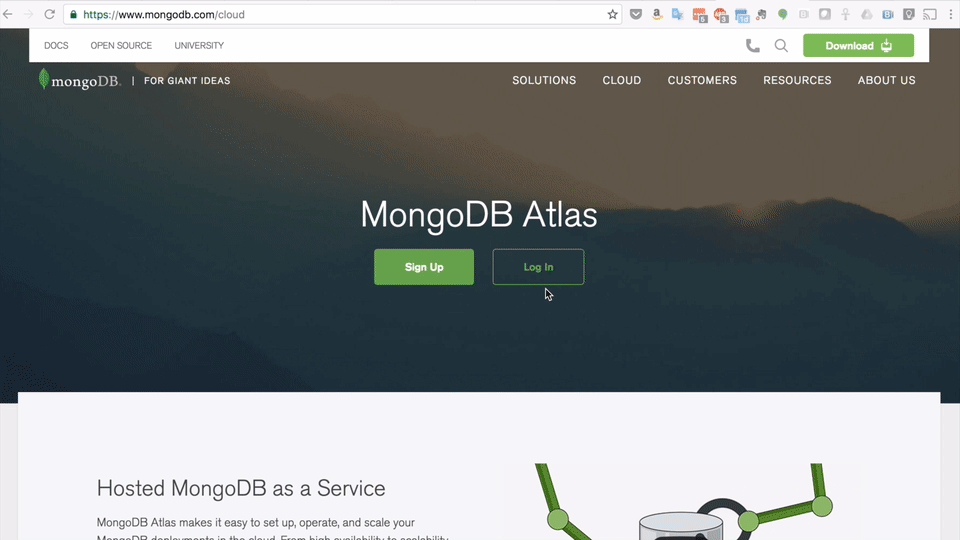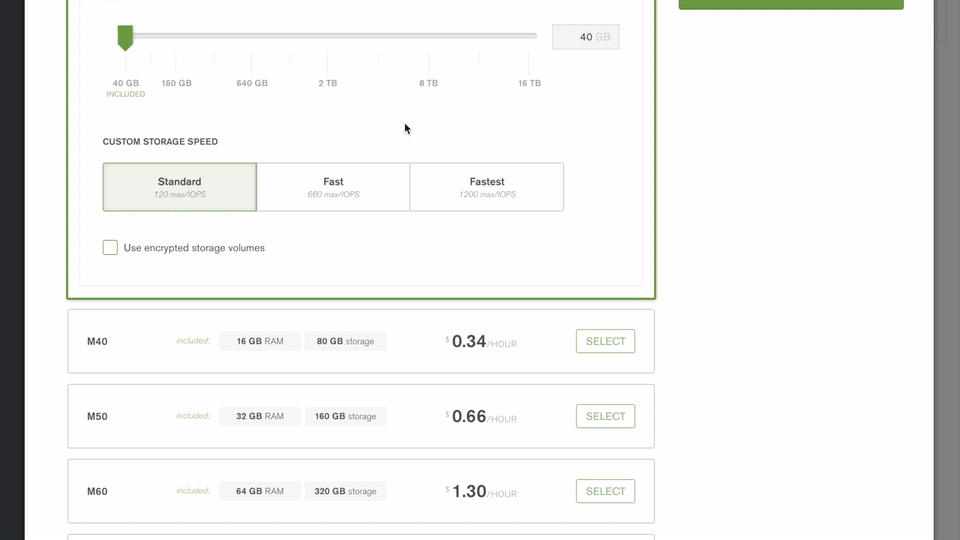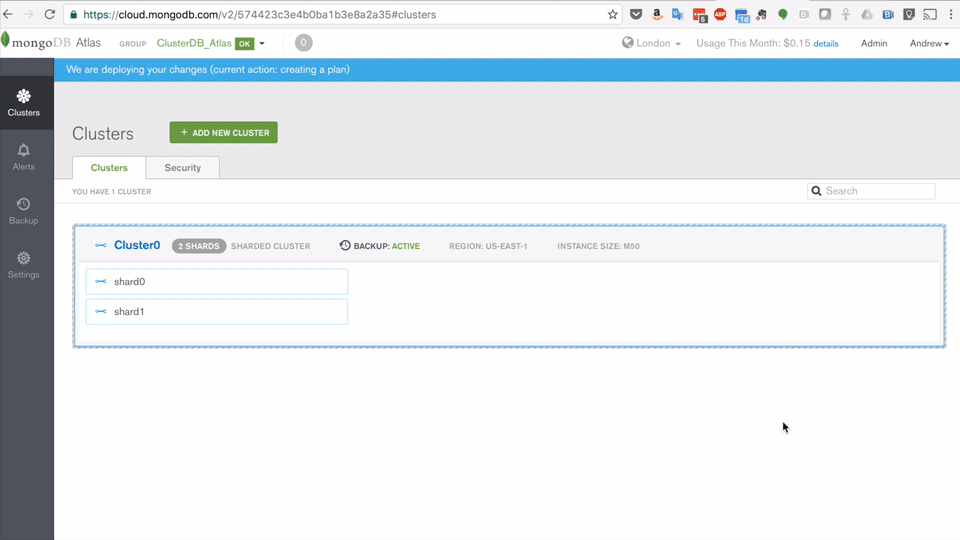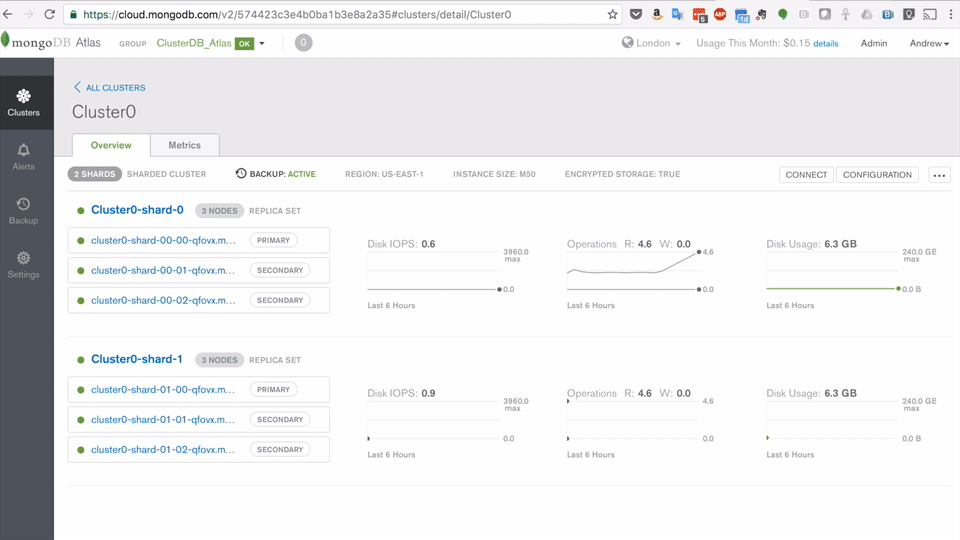
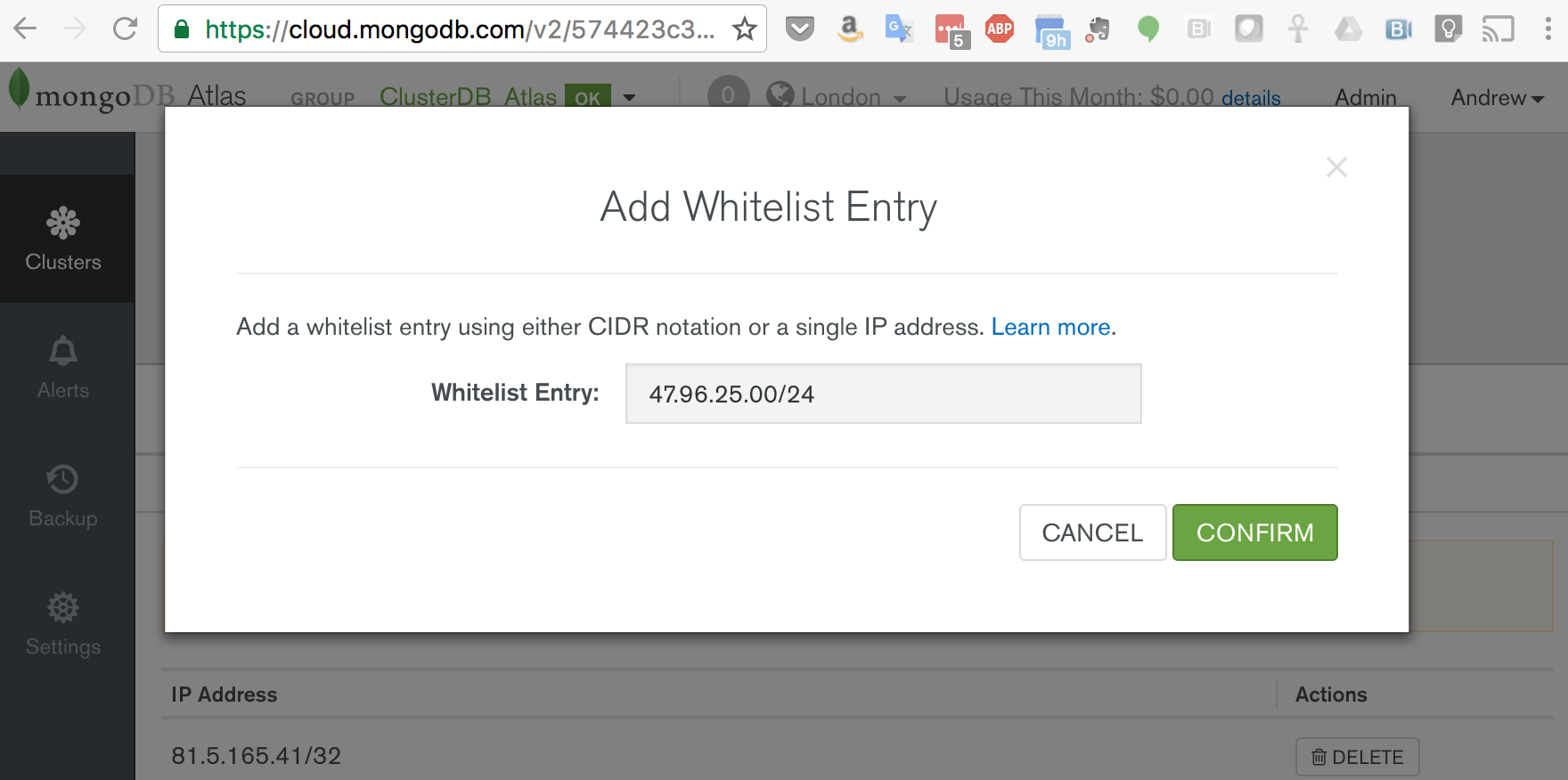
Note that MongoDB Compass currently only accepts a single server address rather than the list of replica set members in the standard Atlas connect string and so it’s necessary to explicitly provide Compass with the address of the current primary – find that by clicking on the cluster in the Atlas GUI (Figure 1).
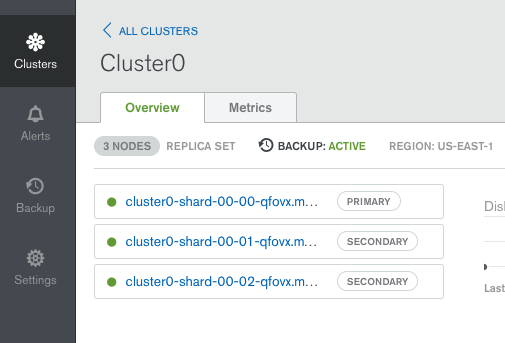
Figure 1: Identify the replica set primary
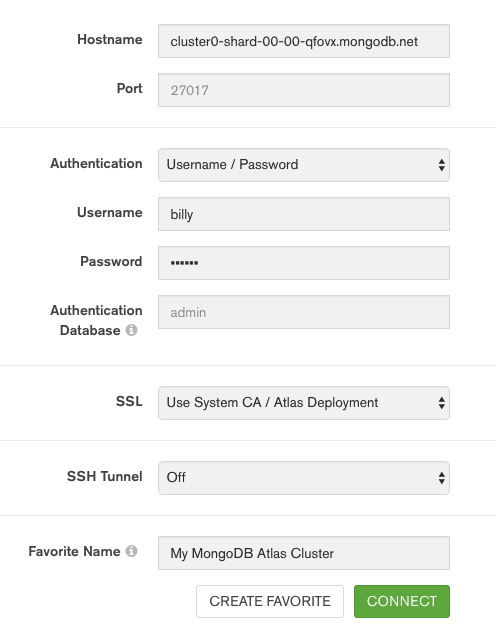
Figure 2: Connect MongoDB Compass to MongoDB Atlas
The connection panel can then be populated as shown in Figure 2.
Load Data and Check in MongoDB Compass
If you don’t already have a populated MongoDB collection, create one now. For example, use curl to download a pre-prepared JSON file containing contact data and use mongoimport to load it into your database:
curl -o contacts.json http://clusterdb.com/upload/contacts.json
mongoimport -h cluster0-shard-00-00-qfovx.mongodb.net -d clusterdb -c contacts --ssl -u billy -p SECRET --authenticationDatabase admin contacts.json
Connect MongoDB Compass to your database (Figure 3).
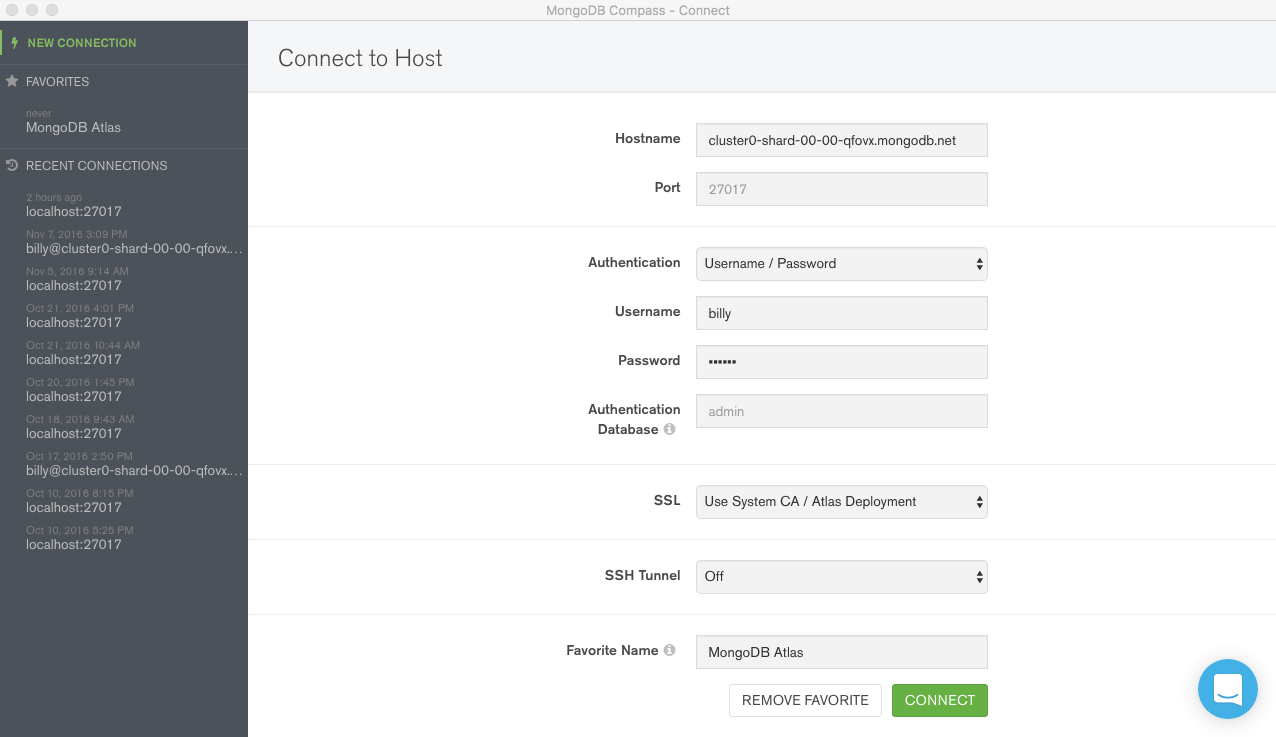
Figure 3: Connect MongoDB Compass to database
Select the contacts data and browse the schema (Figure 4).
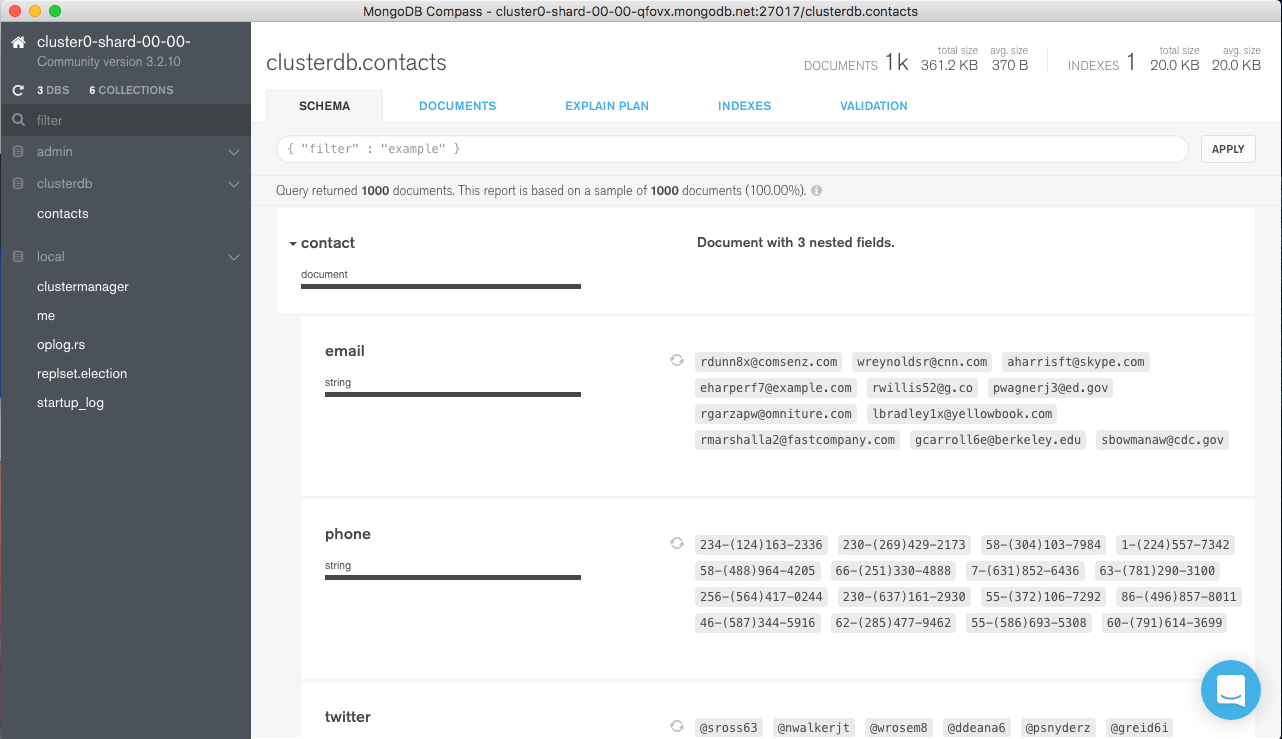
Figure 4: Check schema in MongoDB Compass
Browse some documents (Figure 5).
Figure 5: Browse documents using MongoDB Compass
Add Document Validation Rules
In this section, we build the document validation rule shown earlier.
Navigate to the Validation tab in MongoDB Compass GUI and select the desired validation action and validation level. The effects of these settings are shown in Figure 6. Any warnings generated by the rules are written to the MongoDB log.
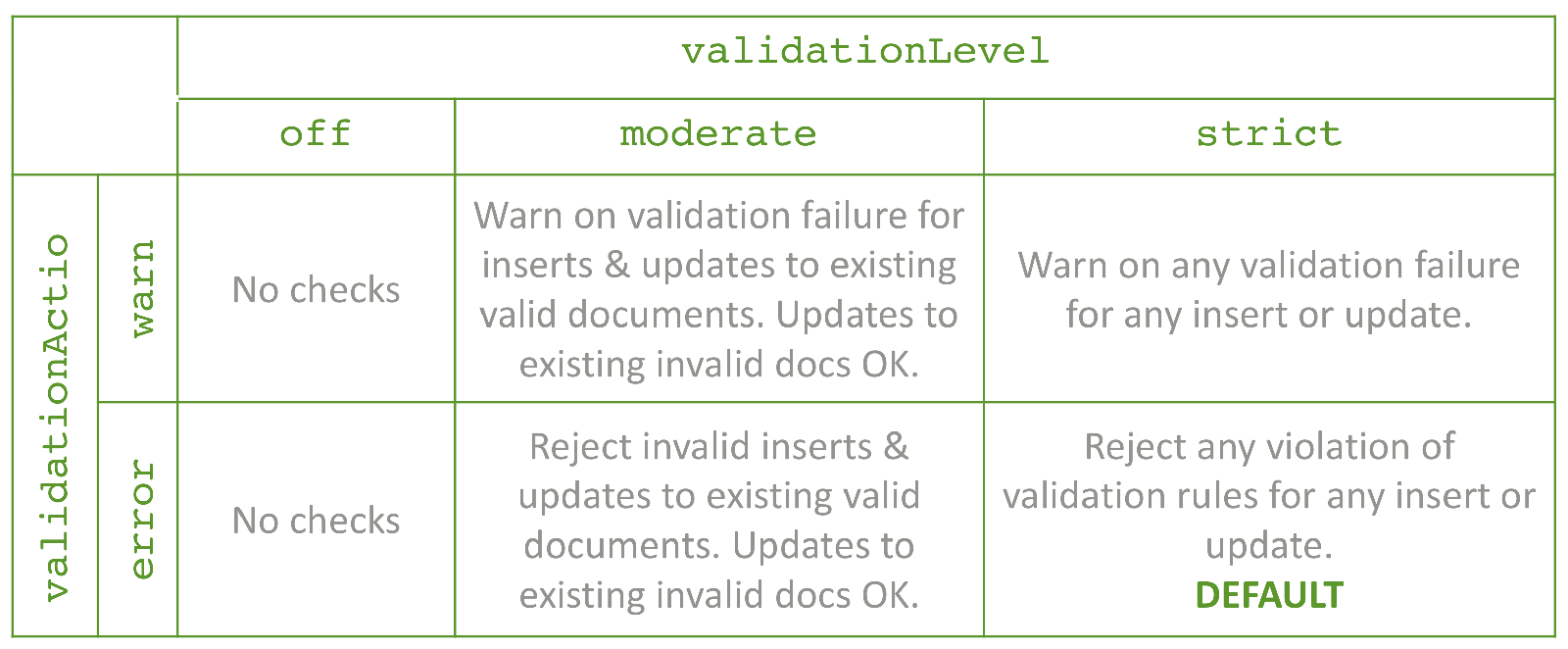
Figure 6: MongoDB document validation configuration parameters
When adding document validation rules to an existing collection, you may want to start with fairly permissive rules so that existing applications aren’t broken before you have chance to clean things up. Once you’re confident that all applications are following the rules you could then become stricter. Figure 7 shows a possible life cycle for a collection.

Figure 7: Life cycle of a MongoDB collection
This post is starting with a new collection and so you can go straight to error/strict as shown in Figure 8.

Figure 8: Set document validation to error/strict
Multiple rules for the document can then be added using the GUI (Figure 9). Note that the rule for the email address uses a regular expression (^([a-zA-Z0-9_\\-\\.]+)@((\\[[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}\\.)|(([a-zA-Z0-9\\-]+\\.)+))([a-zA-Z]{2,4}|[0-9]{1,3})(\\]?)$) to test that the address is properly formatted – going further than the original rule.
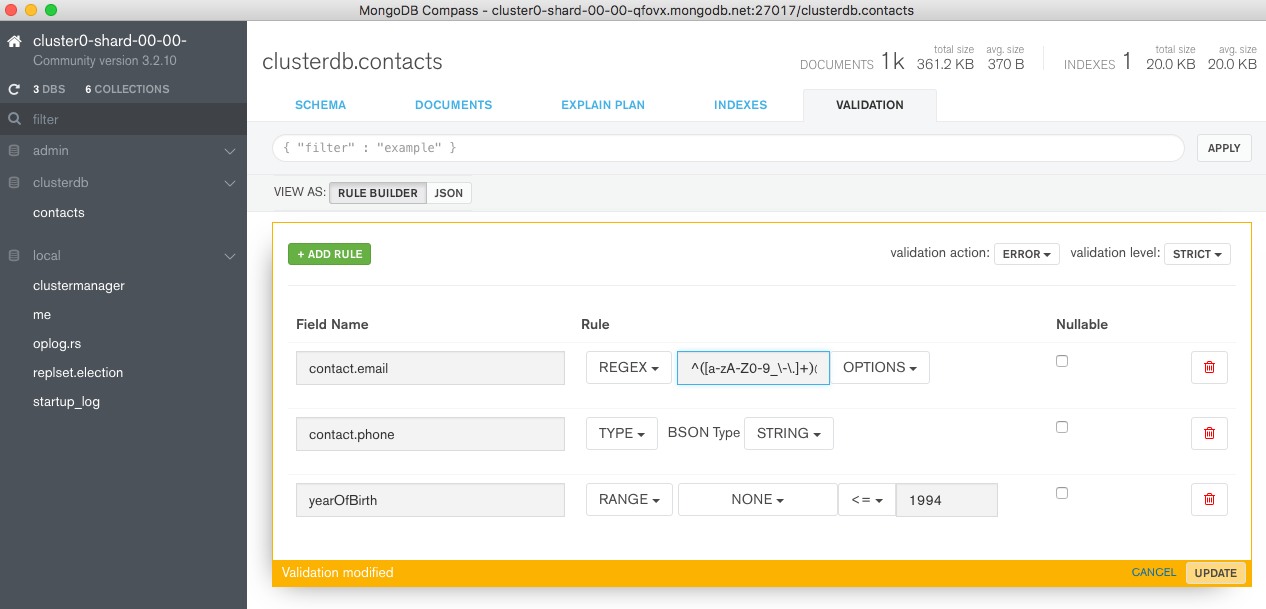
Figure 9: Add new document validation rule through MongoDB Compass
Clicking UPDATE applies the change and then you can review it by pressing the JSON button (Figure 10).
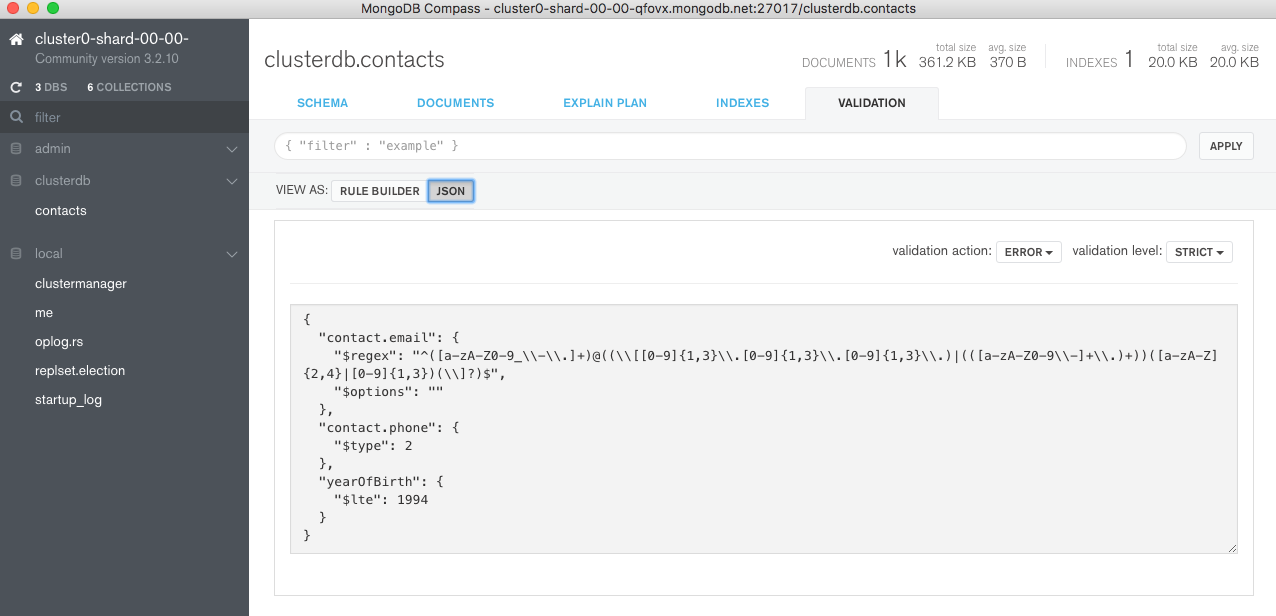
Figure 10: JSON view of new document validation rule
At this point, a problem appears. Compass has combined the 3 sub-rules with an and relationship but our intent was to test that the document contained either an email address or a phone number and that yearOfBirth was no later than 1994. Fortunately, for these more complex checks, the JSON can be altered directly within Compass:
{
"$and": [
{"yearOfBirth": {"$lte": 1994}},
{
"$or": [
{"contact.email": {
"$regex": "^([a-zA-Z0-9_\\-\\.]+)@((\\[[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}\\.)|(([a-zA-Z0-9\\-]+\\.)+))([a-zA-Z]{2,4}|[0-9]{1,3})(\\]?)$",
"$options": ""
}
},
{
"$and": [
{"contact.phone": {"$type": 2}},
{"contact.email": {"$exists": false}}
]
}
]
}
]
}
Paste the refined rule into Compass and press UPDATE (Figure 11).
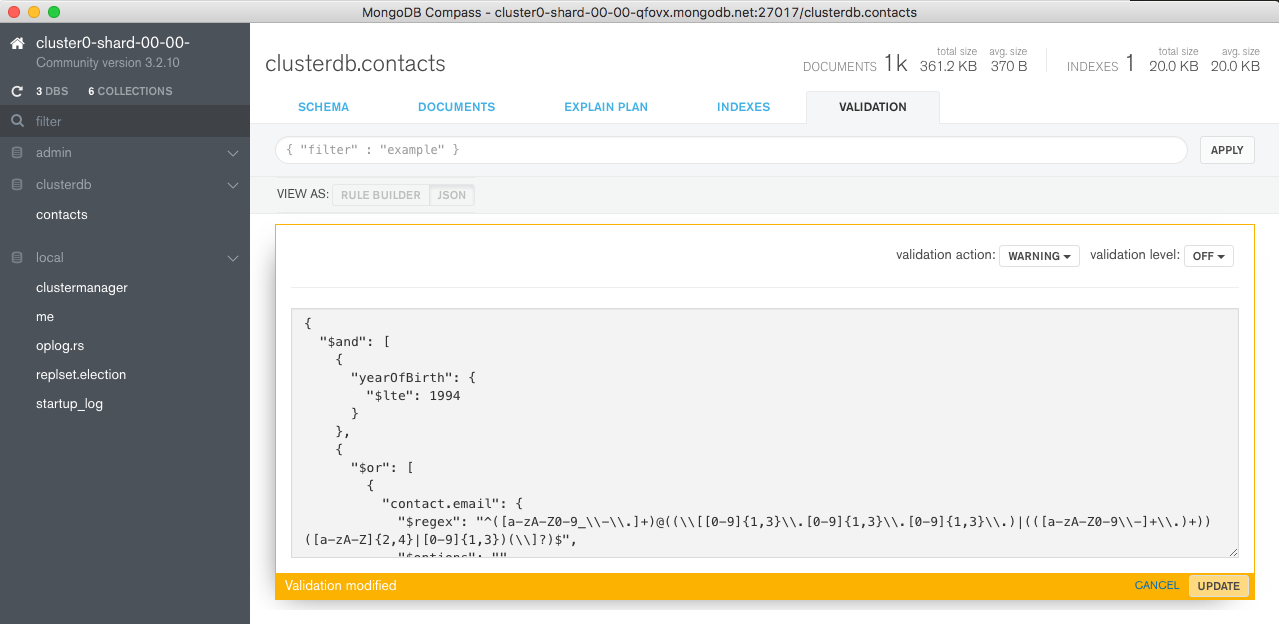
Figure 11: Manually edit validation rules in MongoDB Compass
Recall that this rule checks that the yearOfBirth is no later than 1994 and that there is a phone number (formatted as a string)or a properly formatted email address.
Test The Rules
However you write to the database, the document validation rules are applied in the same way – through any of the drivers, or through the mongo shell. For this post we can test the rules directly from the MongoDB Compass GUI, from the DOCUMENTS tab. Select a document and try changing the yearOfBirth to a year later than 1994 as shown in Figure 12.
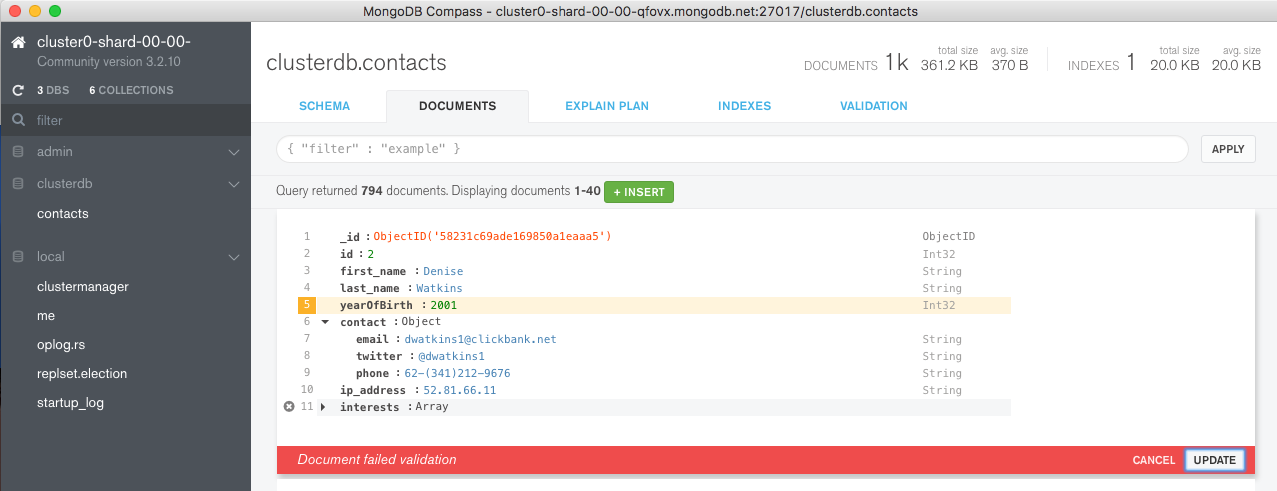
Figure 12: Change fails document validation
Find the Offending Documents Already in the Collection
There are a number of ways to track down existing documents that don’t meet the new rules. A very simple option is to query the database using the negation of the rule definition by wrapping the validation document in a $nor clause:
{"$nor": [
{
"$and": [
{"yearOfBirth": {"$lte": 1994}},
{
"$or": [
{"contact.email": {
"$regex": "^([a-zA-Z0-9_\\-\\.]+)@((\\[[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}\\.)|(([a-zA-Z0-9\\-]+\\.)+))([a-zA-Z]{2,4}|[0-9]{1,3})(\\]?)$",
"$options": ""
}
},
{"contact.phone": {"$type": 2}}
]
}
]
}]
}
The query document can be pasted into the query bar in Compass and then pressing APPLY reveals that there are 206 documents with yearOfBirth greater than 1994 – Figure 13.
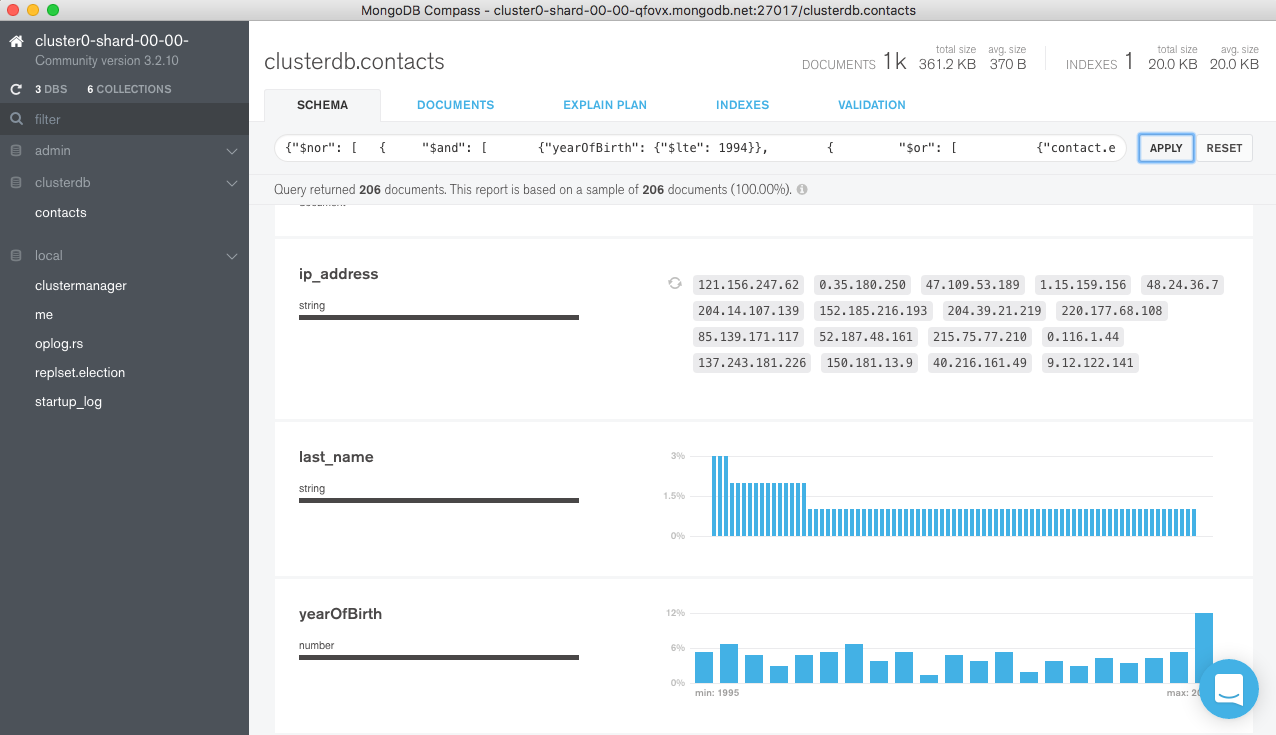
Figure 13: Find documents not matching the validation rules
Cleaning up Offending Documents
Potentially more problematic is how to clean up the existing documents which do not match the validation rules, as you need to decide what should happen to them. The good news is that the same $nor document used above can be used as a filter when executing your chosen action.
For example, if you decided that the offending documents should not be in the collection at all then this command can be run from the mongo shell command line to delete them:
use clusterdb
db.contacts.remove(
{"$nor": [
{
"$and": [
{"yearOfBirth": {"$lte": 1994}},
{
"$or": [
{"contact.email": {
"$regex": "^([a-zA-Z0-9_\\-\\.]+)@((\\[[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}\\.)|(([a-zA-Z0-9\\-]+\\.)+))([a-zA-Z]{2,4}|[0-9]{1,3})(\\]?)$",
"$options": ""
}
},
{"contact.phone": {"$type": 2}}
]
}
]
}]
})
Another Example – Coping with Multiple Schema Versions
A tricky problem to solve with RDBMSs is the versioning of data models; with MongoDB it’s very straight-forward to set up validations that can cope with different versions of documents, with each version having a different set of checks applied. In the example validation checks below, the following logic is applied:
- If the document is unversioned (possibly dating to the time before validations were added), then no checks are applied
- For version 1, the document is checked to make sure that the
namekey exists - For version 2 documents, the type of the
namekey is also validated to ensure that it is a string
{"$or": [
{version: {"$exists": false}},
{"$and": [
{version: 1},
{Name: {"$exists": true}}
]},
{"$and": [
{version: 2},
{Name: {"$exists": true, "$type": "string"}}
]}
]}
In this way, multiple versions of documents can exist within the same collection, and the application can lazily up-version them over time. Note that the version attribute is user-defined.
Where MongoDB Document Validation Excels (vs. RDBMSs)
In MongoDB, document validation is simple to set up – especially now that it can be done through the MongoDB Compass GUI. You can avoid the maintenance headache of stored procedures – which for many types of validation would be required in an RDBMS – and because the familiar MongoDB query language is used, there is no new syntax to learn.
The functionality is very flexible and it can enforce constraints on as little or as much of the schema as required. You get the best of both worlds – a dynamic schema for rapidly changing, polymorphic data, with the option to enforce strict validation checks against specific attributes from the onset of your project, or much later on. You can also use the Compass GUI to find and modify individual, pre-existing documents that don’t follow any new rules. If you initially have no validations defined, they can still be added later – even once in production, across thousand of servers.
It is always a concern whether adding extra checks will impact the performance of the system; in our tests, document validation adds a negligible overhead.
So, is all Data Validation Now Done in the Database?
The answer is “probably not” – either because there’s a limit to what can be done in the database or because there will always be a more appropriate place for some checks. Here are some areas to consider:
- For a good user experience, checks should be made as early and as high up the stack as is sensible. For example, the format of an entered email address should be first checked in the browser rather than waiting for the request to be processed and an attempt made to write it to the database.
- Any validations which need to compare values between keys, other documents, or external information cannot currently be implemented within the database.
- Many checks are best made within the application’s business logic – for example “is this user allowed to use these services in their home country”; the checks in the database are primarily there to protect against coding errors.
- If you need information on why the document failed validation, the developer or application will need to check the document against each of the sub-rules within the collection’s validation rule in turn as the error message doesn’t currently give this level of detail.
Summary
In this post, we’ve taken a look at the powerful document validation functionality that was added back in MongoDB 3.2. We then explored how MongoDB Compass 1.5 adds the convenience of being able to define these rules through an intuitive GUI.
This is just one of the recent enhancements to MongoDB Compass; others include:
- Create, remove, update, delete, or clone existing documents
- Provide real-time performance statistics
- Visualize query explain plans
- Review index usage
- Create new indexes
A summary of the enhancements added in MongoDB Compass 1.4 & 1.5 can be found in MongoDB 3.4 – What’s New.