Memcached API with Cluster Data Nodes
The native Memcached API for MySQL Cluster is now GA as part of MySQL Cluster 7.2
This post was first published in April 2011 when the first trial version of the Memcached API for MySQL Cluster was released; it was then up-versioned for the second MySQL Cluster 7.2 Development Milestone Release in October 2011. I’ve now refreshed the post based on the GA of MySQL Cluster 7.2 which includes the completed Memcache API.
There are a number of attributes of MySQL Cluster that make it ideal for lots of applications that are considering NoSQL data stores. Scaling out capacity and performance on commodity hardware, in-memory real-time performance (especially for simple access patterns), flexible schemas… sound familiar? In addition, MySQL Cluster adds transactional consistency and durability. In case that’s not enough, you can also simultaneously combine various NoSQL APIs with full-featured SQL – all working on the same data set. This post focuses on a new Memcached API that is now available to download, try out and deploy. This post steps through setting up Cluster with the Memcached API and then demonstrates how to read and write the same data through both Memcached and SQL (including for existing MySQL Cluster tables).
Download the community version from mysql.com or the commercial version from Oracle’s Software Delivery Cloud (note that there is not currently a Windows version).

Traditional use of Memcached
First of all a bit of background about Memcached. It has typically been used as a cache when the performance of the database of record (the persistent database) cannot keep up with application demand. When changing data, the application will push the change to the database, when reading data, the application first checks the Memached cache, if it is not there then the data is read from the database and copied into Memcached. If a Memcached instance fails or is restarted for maintenance reasons, the contents are lost and the application will need to start reading from the database again. Of course the database layer probably needs to be scaled as well so you send writes to the master and reads to the replication slaves.
This has become a classic architecture for web and other applications and the simple Memcached attribute-value API has become extremely popular amongst developers.
As an illustration of the simplicity of this API, the following example stores and then retrieves the string “Maidenhead” against the key “Test”:
telnet localhost 11211
set Test 0 0 10
Maidenhead!
END
get Test
VALUE Test 0 10
Maidenhead!
END
Note that if we kill and restart the memcached server, the data is lost (as it was only held in RAM):
get Test
END
New options for using Memcached API with MySQL Cluster

Architecture for Memcached NDB API
What we’re doing with MySQL Cluster is to offer a bunch of new ways of using this API but with the benefits of MySQL Cluster. The solution has been designed to be very flexible, allowing the application architect to find a configuration that best fits their needs.
A quick diversion on how this is implemented. The application sends reads and writes to the memcached process (using the standard Memcached API). This in turn invokes the Memcached Driver for NDB (which is part of the same process) which in turn calls the NDB API for very quick access to the data held in MySQL Cluster’s data nodes (it’s the fastest way of accessing MySQL Cluster).
Because the data is now stored in MySQL Cluster, it is persistent and you can transparently scale out by adding more data nodes (this is an on-line operation).
Another important point is that the NDB API is already a commonly used, fully functional access method that the Memcached API can exploit. For example, if you make a change to a piece of data then the change will automatically be written to any MySQL Server that has its binary logging enabled which in turn means that the change can be replicated to a second site.
Memcached API with Cluster Data Nodes
So the first (and probably simplest) architecture is to co-locate the Memcached API with the data nodes.
The applications can connect to any of the memcached API nodes – if one should fail just switch to another as it can access the exact same data instantly. As you add more data nodes you also add more memcached servers and so the data access/storage layer can scale out (until you hit the 48 data node limit).

Memcached server with the Application
Another simple option is to co-locate the Memcached API with the application. In this way, as you add more application nodes you also get more Memcached throughput. If you need more data storage capacity you can independently scale MySQL Cluster by adding more data nodes. One nice feature of this approach is that failures are handled very simply – if one App/Memcached machine should fail, all of the other applications just continue accessing their local Memcached API.

Separate Memcached layer
For maximum flexibility, you can have a separate Memcached layer so that the application, the Memcached API & MySQL Cluster can all be scaled independently.
In all of the examples so far, there has been a single source for the data (it’s all held in MySQL Cluster).

Local Cache in Memcached
If you choose, you can still have all or some of the data cached within the memcached server (and specify whether that data should also be persisted in MySQL Cluster) – you choose how to treat different pieces of your data. If for example, you had some data that is written to and read from frequently then store it just in MySQL Cluster, if you have data that is written to rarely but read very often then you might choose to cache it in Memcached as well and if you have data that has a short lifetime and wouldn’t benefit from being stored in MySQL Cluster then only hold it in Memcached. The beauty is that you get to configure this on a per-key-prefix basis (through tables in MySQL Cluster) and that the application doesn’t have to care – it just uses the Memcached API and relies on the software to store data in the right place(s) and to keep everything in sync.
Of course if you want to access the same data through SQL then you’d make sure that it was configured to be stored in MySQL Cluster.
Enough of the theory, how to try it out…
Installing & configuarying the software
As this post is focused on API access to the data rather than testing High Availability, performance or scalability the Cluster can be kept extremely simple with all of the processes (nodes) running on a single server. The only thing to be careful of when you create your Cluster is to make sure that you define at least 5 API sections (e.g. [mysqld]) in your configuration file so you can access using SQL and 2 Memcached servers (each uses 2 connections) at the same time.
For further information on how to set up a single-host Cluster, refer to this post or just follow the next few steps.
Create a config.ini file for the Cluster configuration:
[ndb_mgmd]
hostname=localhost
datadir=/home/billy/my_cluster/ndb_data
NodeId=1
[ndbd default]
noofreplicas=2
datadir=/home/billy/my_cluster/ndb_data
[ndbd]
hostname=localhost
NodeId=3
[ndbd]
hostname=localhost
NodeId=4
[mysqld]
NodeId=50
[mysqld]
NodeId=51
[mysqld]
NodeId=52
[mysqld]
NodeId=53
[mysqld]
NodeId=54
and a my.cnf file for the MySQL server:
[mysqld]
ndbcluster
datadir=/home/billy/my_cluster/mysqld_data
Before starting the Cluster, install the standard databases for the MySQL Server (from wherever you have MySQL Cluster installed – typically /usr/local/mysql):
[billy@ws2 mysql]$ ./scripts/mysql_install_db
--basedir=/usr/local/mysql
--datadir=/home/billy/my_cluster/mysqld_data
--user=billy
Start up the system
We are now ready to start up the Cluster processes:
[billy@ws2 my_cluster]$ ndb_mgmd -f conf/config.ini
--initial --configdir=/home/billy/my_cluster/conf/
[billy@ws2 my_cluster]$ ndbd
[billy@ws2 my_cluster]$ ndbd
[billy@ws2 my_cluster]$ ndb_mgm -e show # Wait for data nodes to start
[billy@ws2 my_cluster]$ mysqld --defaults-file=conf/my.cnf &
If your version doesn’t already have the ndbmemcache database installed then that should be your next step:
[billy@ws2 ~]$ mysql -h 127.0.0.1 -P3306 -u root < /usr/local/mysql/share/memcache-api/ndb_memcache_metadata.sql
After that, start the Memcached server (with the NDB driver activated):
[billy@ws2 ~]$ memcached -E /usr/local/mysql/lib/ndb_engine.so -e "connectstring=localhost:1186;role=db-only" -vv -c 20
Notice the “connectstring” – this allows the primary Cluster to be on a different machine to the Memcached API. Note that you can actually use the same Memcached server to access multiple Clusters – you configure this within the ndbmemcached database in the primary Cluster. In a production system you may want to include reconf=false amogst the -e parameters in order to stop configuration changes being applied to running Memcached servers (you’d need to restart those servers instead).
Try it out!
Next the fun bit – we can start testing it out:
[billy@ws2 ~]$ telnet localhost 11211
set maidenhead 0 0 3
SL6
STORED
get maidenhead
VALUE maidenhead 0 3
SL6
END
We can now check that the data really is stored in the database:
mysql> SELECT * FROM ndbmemcache.demo_table;
+------------------+------------+-----------------+--------------+
| mkey | math_value | cas_value | string_value |
+------------------+------------+-----------------+--------------+
| maidenhead | NULL | 263827761397761 | SL6 |
+------------------+------------+-----------------+--------------+
Of course, you can also modify this data through SQL and immediately see the change through the Memcached API:
mysql> UPDATE ndbmemcache.demo_table SET string_value='sl6 4' WHERE mkey='maidenhead';
[billy@ws2 ~]$ telnet localhost 11211
get maidenhead
VALUE maidenhead 0 5
SL6 4
END
By default, the normal limit of 14K per row still applies when using the Memcached API; however, the standard configuration treats any key-value pair with a key-pefix of “b:” differently and will allow the value to be up to 3 Mb (note the default limit imposed by the Memcached server is 1 Mb and so you’d also need to raise that). Internally the contents of this value will be split between 1 row in ndbmemcache.demo_table_large and one or more rows in ndbmemcache.external_values.
Note that this is completely schema-less, the application can keep on adding new key/value pairs and they will all get added to the default table. This may well be fine for prototyping or modest sized databases. As you can see this data can be accessed through SQL but there’s a good chance that you’ll want a richer schema on the SQL side or you’ll need to have the data in multiple tables for other reasons (for example you want to replicate just some of the data to a second Cluster for geographic redundancy or to InnoDB for report generation).
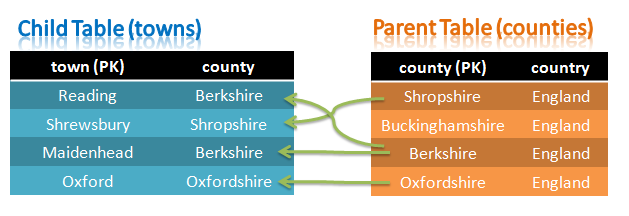
The next step is to create your own databases and tables (assuming that you don’t already have them) and then create the definitions for how the app can get at the data through the Memcached API. First let’s create a table that has a couple of columns that we’ll also want to make accessible through the Memcached API:
mysql> CREATE DATABASE clusterdb; USE clusterdb;
mysql> CREATE TABLE towns_tab (town VARCHAR(30) NOT NULL PRIMARY KEY,
zip VARCHAR(10), population INT, county VARCHAR(10)) ENGINE=NDB;
mysql> REPLACE INTO towns_tab VALUES ('Marlow', 'SL7', 14004, 'Berkshire');
Next we need to tell the NDB driver how to access this data through the Memcached API. Two ‘containers’ are created that identify the columns within our new table that will be exposed. We then define the key-prefixes that users of the Memcached API will use to indicate which piece of data (i.e. database/table/column) they are accessing:
mysql> USE ndbmemcache;
mysql> REPLACE INTO containers VALUES ('towns_cnt', 'clusterdb',
'towns_tab', 'town', 'zip', 0, NULL, NULL, NULL, NULL);
mysql> REPLACE INTO containers VALUES ('pop_cnt', 'clusterdb',
'towns_tab', 'town', 'population', 0, NULL, NULL, NULL, NULL);
mysql> SELECT * FROM containers;
+------------+-------------+------------------+-------------+----------------+-------+------------------+------------+--------------------+-----------------------------+
| name | db_schema | db_table | key_columns | value_columns | flags | increment_column | cas_column | expire_time_column | large_values_table |
+------------+-------------+------------------+-------------+----------------+-------+------------------+------------+--------------------+-----------------------------+
| demo_ext | ndbmemcache | demo_table_large | mkey | string_value | 0 | NULL | cas_value | NULL | ndbmemcache.external_values |
| towns_cnt | clusterdb | towns_tab | town | zip | 0 | NULL | NULL | NULL | NULL |
| demo_table | ndbmemcache | demo_table | mkey | string_value | 0 | math_value | cas_value | NULL | NULL |
| pop_cnt | clusterdb | towns_tab | town | population | 0 | NULL | NULL | NULL | NULL |
| demo_tabs | ndbmemcache | demo_table_tabs | mkey | val1,val2,val3 | flags | NULL | NULL | expire_time | NULL |
+------------+-------------+------------------+-------------+----------------+-------+------------------+------------+--------------------+-----------------------------+
mysql> REPLACE INTO key_prefixes VALUES (1, 'twn_pr:', 0,
'ndb-only', 'towns_cnt');
mysql> REPLACE INTO key_prefixes VALUES (1, 'pop_pr:', 0,
'ndb-only', 'pop_cnt');
mysql> SELECT * FROM key_prefixes;
+----------------+------------+------------+---------------+------------+
| server_role_id | key_prefix | cluster_id | policy | container |
+----------------+------------+------------+---------------+------------+
| 1 | pop_pr: | 0 | ndb-only | pop_cnt |
| 0 | t: | 0 | ndb-test | demo_tabs |
| 3 | | 0 | caching | demo_table |
| 0 | | 0 | ndb-test | demo_table |
| 0 | mc: | 0 | memcache-only | NULL |
| 1 | b: | 0 | ndb-only | demo_ext |
| 2 | | 0 | memcache-only | NULL |
| 1 | | 0 | ndb-only | demo_table |
| 0 | b: | 0 | ndb-test | demo_ext |
| 3 | t: | 0 | caching | demo_tabs |
| 1 | t: | 0 | ndb-only | demo_tabs |
| 4 | | 0 | ndb-test | demo_ext |
| 1 | twn_pr: | 0 | ndb-only | towns_cnt |
| 3 | b: | 0 | caching | demo_ext |
+----------------+------------+------------+---------------+------------+
At present it is necessary to restart the Memcached server in order to pick up the new key_prefix (and so you’d want to run multiple instances in order to maintain service):
[billy@ws2:~]$ memcached -E /usr/local/mysql/lib/ndb_engine.so -e "connectstring=localhost:1186;role=db-only" -vv -c 20
07-Feb-2012 11:22:29 GMT NDB Memcache 5.5.19-ndb-7.2.4 started [NDB 7.2.4; MySQL 5.5.19]
Contacting primary management server (localhost:1186) ...
Connected to "localhost:1186" as node id 51.
Retrieved 5 key prefixes for server role "db-only".
The default behavior is that:
GET uses NDB only
SET uses NDB only
DELETE uses NDB only.
The 4 explicitly defined key prefixes are "b:" (demo_table_large), "pop_pr:" (towns_tab),
"t:" (demo_table_tabs) and "twn_pr:" (towns_tab)
Now these columns (and the data already added through SQL) are accessible through the Memcached API:
[billy@ws2 ~]$ telnet localhost 11211
get twn_pr:Marlow
VALUE twn_pr:Marlow 0 3
SL7
END
set twn_pr:Maidenhead 0 0 3
SL6
STORED
set pop_pr:Maidenhead 0 0 5
42827
STORED
and then we can check these changes through SQL:
mysql> SELECT * FROM clusterdb.towns_tab;
+------------+------+------------+-----------+
| town | zip | population | county |
+------------+------+------------+-----------+
| Maidenhead | SL6 | 42827 | NULL |
| Marlow | SL7 | 14004 | Berkshire |
+------------+------+------------+-----------+
One final test is to start a second memcached server that will access the same data. As everything is running on the same host, we need to have the second server listen on a different port:
[billy@ws2 ~]$ memcached -E /usr/local/mysql/lib/ndb_engine.so
-e "connectstring=localhost:1186;role=db-only" -vv -c 20
-p 11212 -U 11212
[billy@ws2 ~]$ telnet localhost 11212
get twn_pr:Marlow
VALUE twn_pr:Marlow 0 3
SL7
END

Memcached alongside NoSQL & SQL APIs
As mentioned before, there’s a wide range of ways of accessing the data in MySQL Cluster – both SQL and NoSQL. You’re free to mix and match these technologies – for example, a mission critical business application using SQL, a high-running web app using the Memcached API and a real-time application using the NDB API. And the best part is that they can all share the exact same data and they all provide the same HA infrastructure (for example synchronous replication and automatic failover within the Cluster and geographic replication to other clusters).
Finally, a reminder – please try this out and let us know what you think (or if you don’t have time to try it then let us now what you think anyway) by adding a comment to this post.
 On Thursday 22nd May I’ll be hosting a webinar explaining how you can get the best from the NoSQL world while still getting all of the benefits of a proven RDBMS. As always the webinar is free but please register here.
On Thursday 22nd May I’ll be hosting a webinar explaining how you can get the best from the NoSQL world while still getting all of the benefits of a proven RDBMS. As always the webinar is free but please register here.